
Building an incremental compute engine means constantly asking: is the runtime doing more work than it needs to?” This time the answer was yes.
Incremental join implementation
In an incremental engine, joins don’t work the way they do in a standard database query engine. Instead of scanning entire collections on every query, the engine only processes changes (insertions and deletions) and propagates them throughout the pipeline. The most common type of join is an equi-join, where the condition is one or more equality comparisons of two fields from the two collections, as in this example:
SELECT e.name, d.budget
FROM employees JOIN departments
ON employees.department_id = departments.idTo do this efficiently, every collection involved in a join has to be maintained as an index, keyed on the join field. Incremental joins work according to the the delta rule, which has been known for a long time:
∆(a ⋈ ∆b) = a ⋈ ∆b + ∆a ⋈ b + ∆a ⋈ ∆b
Here a and b are two collections (“employees” and “departments” from the previous example), and ⋈ is the symbol for join.
Consider the case when we insert a new element in collection a. What is the change produced in the output? The new element has to be compared with every element from the entire collection b, and the matching pairs are added to the output. This is what the term ∆a⋈b actually does: it combines every new element in a (shown by the delta symbol ∆) with all the elements in b.
The symmetric case happens when a new element is added to b, leading to the term a ⋈ ∆b. Finally, when elements are added to both collections, they have to be checked against each other, which gives rise to the term ∆a ⋈ ∆b.
This means the join operator needs to know not only the recent changes (∆a and ∆b), but also it has to keep around both entire collections a and b. The operator does this using an integral operator, by accumulating the changes received to reconstruct the two collections.
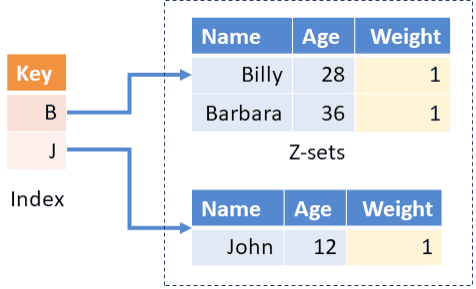
In fact, the Feldera engine represents these two collections as Indexed Z-sets. The collections are indexed using as keys the fields used in the join ON condition, “employees.department_id” and “departments.id” in our example. The incremental dataflow graph for the above query will look as follows (where we have not shown the expansion of the incremental join).

The problem: multiple joins
In large programs, the same collection often ends up participating in multiple joins. For example:
SELECT departments.name, locations.name
FROM departments JOIN locations
ON departments.id = locations.dept_idIn the implementation a program holding both computations will be represented as two incremental joins sharing a source:

Here the collection departments is indexed twice on the same field “id”. The left index of departments maps each department id to all the budgets within the corresponding department (there could be many of them), and the right index of departments maps each department id to all the department names having the given id.
A better way
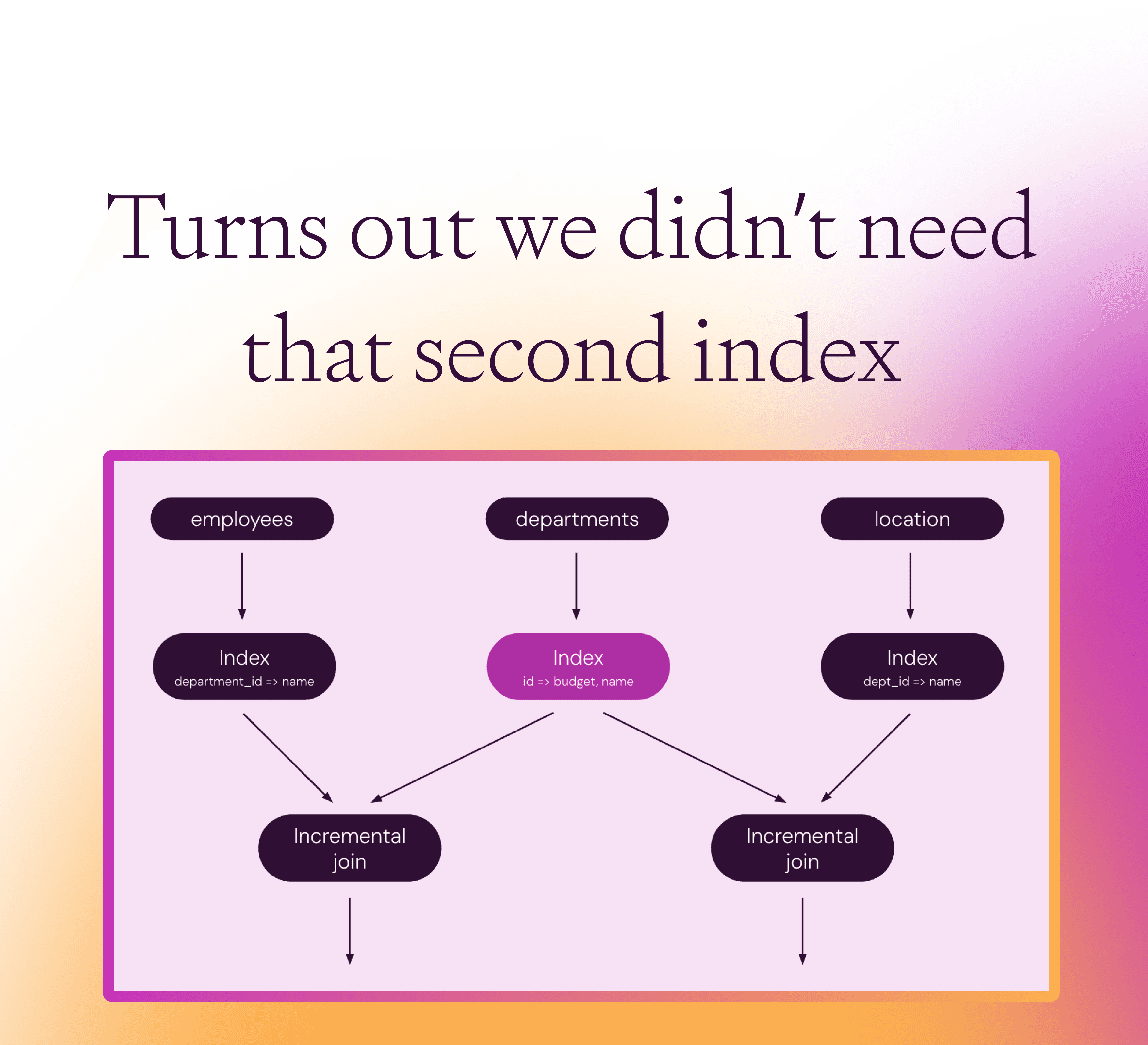
In a recent pull request we have introduced an optimization for this pattern: Feldera's SQL compiler rewrites this pattern to share a single index for departments, which maps the id to a tuple containing both fields needed (budget and name in our example):

When a change to the departments collection is received, the runtime does no longer need to update two indexes; only one index is updated. Moreover, the field “id” is only stored once. The two join operators will share not only the index operator, but also its integral, which stores the content of the departments collection. The combined index is updated twice as fast, and uses less memory than the split indexes.
However, lookup in the index will be slightly slower, since the index is wider, and each join has to be rewritten to only access the fields it needs (budget on the left side).
The space savings can be significant, especially if the collection is very large, or participates in many joins. In some of our programs an index is shared up to 15 times, as shown in the following fragment of a dataflow graph from our test suite (here the operator is a variant of index combined with a previous filter):

What's next
We are working on extending this optimization to encompass indexes used by other operations, such as aggregates, primary key indexes, distinct operators, etc. The principle holds everywhere: if two operators need (almost) the same integral of some collection, there’s no reason to maintain it twice.
This is not a novel optimization; database planners have created shared indexes for a long time. Other incremental engines call this optimization shared arrangements, as described in the following VLDB 2020 paper. Now this is performed automatically by the Feldera compiler.