
Database schemas and their changes
Let us consider a traditional SQL database, such as a database running in Postgres. The schema of the database describes the tables of the database and their structure. Every time we CREATE or DROP a table, we are changing the schema. But in this post we will be concerned only with changes that do not affect the schema, just the tables' contents. (SQL commands which change the database schema are called DDL commands, from Data Definition Language.)
We can use a CREATE command to make a new table:
postgres=# CREATE TABLE Persons(FirstName varchar, LastName varchar);
# CREATE TABLETables and changes to tables
So let us assume that we have a database that contains a table. SQL provides a set of DML (Data Manipulation Language) commands, which are used to modify the contents of tables. The simplest such commands are INSERT and DELETE.
Here is a possible interaction with a Postgres database:
postgres=# SELECT * FROM Persons;
firstname | lastname
-----------+----------
(0 rows)
postgres=# INSERT INTO Persons VALUES('Taylor', 'Swift');
INSERT 0 1
postgres=# SELECT * FROM Persons;
firstname | lastname
-----------+----------
Taylor | Swift
(1 row)
postgres=# INSERT INTO Persons VALUES('Bruce', 'Springsteen');
INSERT 0 1
postgres=# SELECT * FROM Persons;
firstname | lastname
-----------+--------------
Taylor | Swift
Bruce | Springsteen
(2 rows)
postgres=# DELETE FROM Persons WHERE lastname = 'Springsteen';
DELETE 1
postgres=# SELECT * FROM Persons;
firstname | lastname
-----------+----------
Taylor | Swift
(1 row)
postgres=# INSERT INTO Persons VALUES('Taylor', 'Swift');
INSERT 0 1
postgres=# SELECT * FROM Persons;
firstname | lastname
-----------+----------
Taylor | Swift
Taylor | Swift
(2 rows)
postgres=# DELETE FROM Persons WHERE lastname = 'Springsteen';
DELETE 0Let us notice a few things:
- A database table is a collection of rows, all of which have the same "structure" (in our example each row has two fields, both strings, the 'FirstName' and 'LastName').
- a database table is initially empty, having 0 rows
- we can insert rows in a table using the
INSERTcommand - we can delete rows from a table using the
DELETEcommand - a table can have multiple identical rows
Mathematically speaking, a database table is a multiset of rows. It is a multiset because a row can appear more than once, e.g., two "Taylor Swift"s. It is a multiset, and not a list -- for example -- because the order of the rows does not matter -- the first and the second "Taylor Swift" rows are really indistinguishable. Theoreticians also use the term bags instead of multisets.
(We ignore in this post the subject of database keys; a table that has a key becomes just a set, where each row can appear at most once, but sets are just a special case of multisets.)
We have thus seen three kinds of objects:
- tables, which are multisets of rows
- insertions operations, each of which can add a number of rows to a table
- deletions operations, each of which can remove a number of rows from a table
This is somewhat unsatisfactory, because all three of these objects describe some multiset: respectively, the content of a table, the content that is inserted into a table, and the content that is deleted from a table. Is there a better way?
Z-sets
Theoreticians have unified all three objects into a convenient structure, called a Z-set (or sometimes a Z-relation). The first mention I could find of Z-relations is from a paper published in 2009 in the International Conference on Database Theory: Reconciliable Differences, by Todd Green, Zachary Ives and Val Tannen. The paper is pretty deep, but we only need to understand the core concept, which isn't too complicated. The ℤ letter comes from mathematics, where it denotes the set of integer numbers (..., -2, -1, 0, 1, 2, ...)
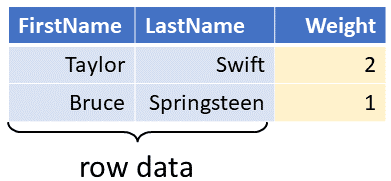
A Z-set looks a lot like a database table, except that to each row we add an integer value, which we call weight.

The weight indicates how many times the row appears in the Z-set. If a row has a weight of 0 we assume it's missing. (To keep things simple, let's also assume that all rows are different when ignoring the weights.)
Here are a few Z-sets corresponding to some of the tables and changes above.
The empty Z-set is a table with no rows:
A Z-set with one row of weight 1:

A Z-set with one row of weight -1, representing the deletion of one row (a negative weight):

Z-sets are very nice. We can use Z-sets to represent all three kinds of objects: tables (i.e., multisets), insertions into tables, and deletions from tables.
- A table is just a Z-set where all the weights are positive
- A deletion is a Z-set where all the weights are negative
- An insertion is also a Z-set where all the weights are positive
Notice that Z-sets can also represent some exotic objects that have no clear counterpart in a database, like multiple insertions and deletions in a single object. (UPDATE operations, which we have not discussed, can be represented as deletions followed by insertions of modified records.)
We can define the mathematical operation plus (+) on Z-sets as follows: to add two z-sets, find all the rows with identical values and add their weights. If a weight becomes 0, the corresponding row is removed.
So we have the following equations:


We can also define the negation of a Z-set as changing the sign of all weights.

The empty Z-set is behaves like the 0 value for addition and subtraction. Thus, computing on Z-sets has thus nice mathematical properties. (The order of elements in an addition does not matter, addition is associative, every Z-set has an inverse. In other words, Z-sets form a mathematical structure called "commutative groups". Don't worry too much if you don't know what that means.)
In future posts we will see how we can take advantage of Z-sets to provide very efficient algorithms for incremental computation on database tables. The next blog post shows how to implement Z-sets in Java.




