
One would think that maintaining a running sum incrementally is easy. It turns out that doing it properly for SQL queries is actually quite tricky. This blog post explains why standard query engines do not support incremental view maintenance for complex queries that include aggregation steps in complex plans.
This is the first in a series of short blog posts about the difficulties of implementing aggregation in an incremental and streaming computation model.
Introduction: SQL Aggregate functions
The SQL language provides a set of built-in operations for summarizing the information of a numeric collection as a single number. For example, the SUM aggregation function will add up all the numbers in a collection.
In SQL, aggregation functions are usually used in combination with the GROUP BY statement, which groups together rows into groups and computes one result for each group. But we can think of aggregation used without GROUP BY as a special case where there is a single group containing all the values in the original collection.
Consider the following SQL program:
CREATE TABLE T(name VARCHAR, salary INT);
INSERT INTO T VALUES('Bob', 100), ('John', 115);
SELECT SUM(salary) AS s FROM T;Executing this program in a regular database will provide as an answer the value 215 = 100 + 115, the sum of all values in the column salary.
How does a database implement a query such as the previous one? It essentially creates a partial result, initialized to 0, and a cursor. The cursor iterates over all rows of the table, retrieving the salary of the row. For each row, the partial result is updated by adding the salary for the current cursor.
If the aggregation function is commutative and associative (or if the order of rows does not matter), a fancy database may even parallelize the process. For SUM, which is commutative and associative for integer numbers, the process may divide the rows of the table into independent groups, compute the sum for each group using a separate thread, and then add up the results. This algorithm needs to look at every row in the input collection, thus it's complexity is O(n), where n is the number of rows in the database. There does not seem to be much that can be done to improve this.
Incremental aggregation
What if we define a view that computes an aggregate? How can the contents of such a view be maintained efficiently when the input tables change?
CREATE VIEW V AS SELECT SUM(salary) AS s FROM T;Let's say that the database system has already computed the contents of view V. Now we execute one more SQL statement:
INSERT INTO T VALUES('Anne', 120)In order to update the contents of the view V the database has to compute the new total. A smart planner will take advantage of the existence of the previous result, and will only add the new value to the previous result, only looking at the new rows, computing 225 + 120 = 345. This is called "incremental view maintenance".
Incremental aggregation in Feldera
In Feldera data (both collections and changes to collections) are represented uniformly as Z-sets. Briefly, Z-sets are tables where each row is accompanied by an integer count, which can be positive or negative. A positive count indicates a row that is being added, a negative count indicates a row that is being removed.
When you create a Feldera pipeline you describe the inputs (CREATE TABLE) and the outputs (CREATE VIEW), providing SQL definitions for all views involved:

Once the pipeline has been defined and compiled, you start it. Initially all tables and views are empty. From now on, the pipeline will run continuously, listening for changes to the tables, and supplying changes to the views.
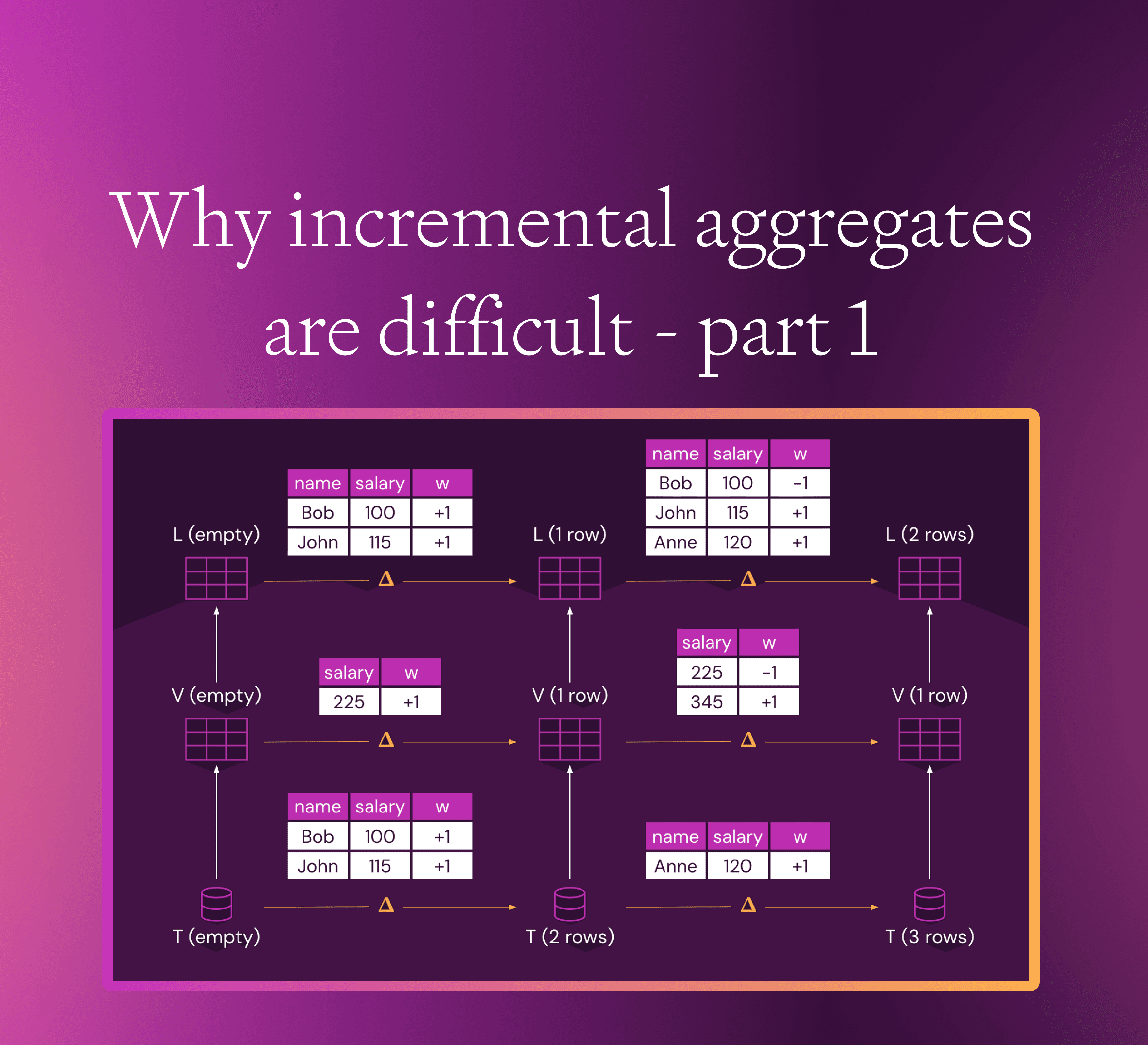
You can supply an initial change inserting the two rows, and the pipeline will supply a view change inserting one row (the orange tables are Z-sets, where the last column shows the weight of each row):

The horizontal arrows indicate changes: the lower arrow shows changes to the tables, and the top arrow shows the changes to the view.
When you supply a second change to the table, by inserting an additional row, something interesting happens:

The view V always contains a single row: the sum of all salaries. Thus, when inserting additional rows in the input table, the Z-set representing the view change contains two rows: a row with weight +1 which inserts the new salary, but also a row with a negative weight -1, which removes the previous salary from the view.
This behavior is true for all aggregate functions, and is not specific to SUM, and it also happens when using GROUP BY: once the value for a group is updated, the previous value has to be removed from the view.
Composing queries
One very nice feature about the design of SQL is that all values produced by queries have the same kind: they are collections (relations, to be more precise). This enables SQL queries to be composed into arbitrary patterns. So a view you define can become an input for another query that computes another view. For example, we create a view showing all huge salaries in the company, which each amount to more than 1/3 of the entire salary budget:
CREATE VIEW L AS
SELECT * FROM T WHERE salary > (SELECT s/3 FROM V);
Many traditional query engines would be able to incrementally update the content of the view V when the table T is modified. However, very few engines would be able to also incrementally update view L, because it requires propagating the deleted rows produced by V through the computation graph.
One of the main contributions of DBSP, the theory underlying the Feldera query engine, is the uniform treatment of insertions and deletions by using Z-sets. This uniform treatment is reflected in the implementation, where all the operators involved in a query plan compute on Z-sets, accepting both positive and negative changes, with no exceptions. And this also explains why it's difficult to retrofit a standard query engine to handle uniformly insertions and deletions: all operator implementations must be modified to accept deletions (negative insertions).
Most relational query operators are monotone, in the sense that when their input collection is larger, their output collection is also larger. You can see this easily for operators such as SELECT, WHERE, GROUP BY, HAVING, etc. But operators such as aggregates and EXCEPT are not monotone. As a consequence, any query that involves such operators may produce deletions even when input data contains insertions. This makes it very difficult to handle incremental updates for such operators in typical query engines.
Another important benefit of computing on Z-sets uniformly is that the algorithms for incremental view maintenance will work for arbitrary input changes (any mix of insertions and deletions). Many traditional query engines may be able to handle only some kinds of input updates incrementally, reverting to full recomputation for the unsupported operations (e.g., deletions).
In future blog posts we will discuss other aspects of incremental evaluation of aggregates which do not surface in traditional query engines.