Part 2: HTTP-based Input and Output
In Part 1 of this tutorial we created a SQL program and ran it as part of a pipeline. We manually pushed data to the pipeline using Feldera Web Console. The next step is to ingest data into SQL tables from external sources and to send query outputs to external sinks. Feldera supports two methods to accomplish this: (1) HTTP-based and (2) connector-based input/output. We cover these two methods in this and the next sections of the tutorial respectively.
In Part 2 of the tutorial we will
Learn to send inputs to and consume outputs from a Feldera pipeline via HTTP.
Introduce another key concept behind Feldera: incremental query evaluation.
Step 1. Restart the pipeline
Start the pipeline you created in Part 1 of the tutorial from a clean state:
- If the pipeline is still running, click to shut it down.
- Click to restart the pipeline.
Step 2. Subscribe to output changes
Subscribe to changes to the PREFERRED_VENDOR view:
curl -s -N -X 'POST' http://localhost:8080/v0/pipelines/supply_chain/egress/PREFERRED_VENDOR?format=json | jq
You should see periodic heartbeat messages:
{
"sequence_number": 0
}
{
"sequence_number": 1
}
{
"sequence_number": 2
}
{
"sequence_number": 3
}
...
Step 3. Populate inputs
In another terminal, use the following command to populate the PART table
with the same data we entered manually in part 1 of the tutorial:
curl -X 'POST' http://localhost:8080/v0/pipelines/supply_chain/ingress/PART?format=json -d '
{"insert": {"id": 1, "name": "Flux Capacitor"}}
{"insert": {"id": 2, "name": "Warp Core"}}
{"insert": {"id": 3, "name": "Kyber Crystal"}}'
The request URL includes the table name (PART) and the input data format
(json). The request payload consists of newline-delimited JSON objects, where
each object specifies a command (in this case, "insert") and a record to insert.
Records are encoded as JSON objects with one key per table column.
Next, we populate the other two tables:
curl -X 'POST' http://localhost:8080/v0/pipelines/supply_chain/ingress/VENDOR?format=json -d '
{"insert": {"id": 1, "name": "Gravitech Dynamics", "address": "222 Graviton Lane"}}
{"insert": {"id": 2, "name": "HyperDrive Innovations", "address": "456 Warp Way"}}
{"insert": {"id": 3, "name": "DarkMatter Devices", "address": "333 Singularity Street"}}'
curl -X 'POST' http://localhost:8080/v0/pipelines/supply_chain/ingress/PRICE?format=json -d '
{"insert": {"part": 1, "vendor": 2, "price": 10000}}
{"insert": {"part": 2, "vendor": 1, "price": 15000}}
{"insert": {"part": 3, "vendor": 3, "price": 9000}}'
You should now see the following output in the terminal that is
listening to changes to the PREFERRED_VENDOR view (the inserts
might appear in a different order):
{
"sequence_number": 9,
"json_data": [
{
"insert": {
"part_id": 1,
"part_name": "Flux Capacitor",
"vendor_id": 2,
"vendor_name": "HyperDrive Innovations",
"price": "10000"
}
}
]
}
{
"sequence_number": 10,
"json_data": [
{
"insert": {
"part_id": 2,
"part_name": "Warp Core",
"vendor_id": 1,
"vendor_name": "Gravitech Dynamics",
"price": "15000"
}
},
{
"insert": {
"part_id": 3,
"part_name": "Kyber Crystal",
"vendor_id": 3,
"vendor_name": "DarkMatter Devices",
"price": "9000"
}
}
]
}
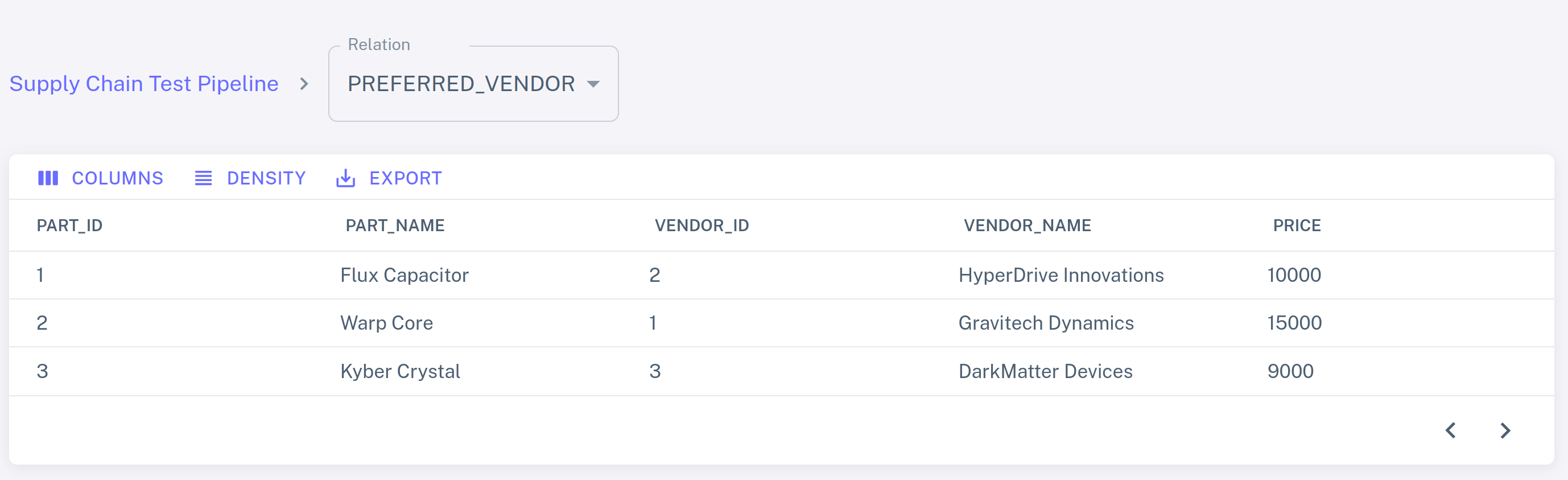
We will learn to decipher this in a moment. Meanwhile, you can use the Feldera
Web Console to inspect tables and views (click on the
icon next to a table or view to inspect it). For instance, here is the contents
of the PREFERRED_VENDOR view:
Step 4. Modify inputs
We already know that Feldera continuously updates output views in response to input changes. But what does this mean exactly? Is it simply a matter of re-running the queries whenever a change occurs? Thankfully, Feldera does something much more efficient.
Let us push some changes to the PRICE table, causing query results to change
(make sure that you are still monitoring the PREFERRED_VENDOR view in a
separate terminal). We use delete commands to remove existing records. Note
that there is no update command. Modifying a record amounts to deleting the
old version and inserting the new one.
curl -X 'POST' http://localhost:8080/v0/pipelines/supply_chain/ingress/PRICE?format=json -d '
{"delete": {"part": 1, "vendor": 2, "price": 10000}}
{"insert": {"part": 1, "vendor": 2, "price": 30000}}
{"delete": {"part": 2, "vendor": 1, "price": 15000}}
{"insert": {"part": 2, "vendor": 1, "price": 50000}}
{"insert": {"part": 1, "vendor": 3, "price": 20000}}
{"insert": {"part": 2, "vendor": 3, "price": 11000}}'
Vendors 1 and 2 have increased their prices, while vendor 3 has added
more parts to its price list, becoming the cheapest supplier of parts
1, 2, and 3. This yields the following output in the
PREFERRED_VENDOR view (the order of the operations might appear
different):
{
"sequence_number": 84,
"json_data": [
{
"delete": {
"PART_ID": 1,
"PART_NAME": "Flux Capacitor",
"PRICE": "10000",
"VENDOR_ID": 2,
"VENDOR_NAME": "HyperDrive Innovations"
}
},
{
"insert": {
"PART_ID": 1,
"PART_NAME": "Flux Capacitor",
"PRICE": "20000",
"VENDOR_ID": 3,
"VENDOR_NAME": "DarkMatter Devices"
}
},
{
"delete": {
"PART_ID": 2,
"PART_NAME": "Warp Core",
"PRICE": "15000",
"VENDOR_ID": 1,
"VENDOR_NAME": "Gravitech Dynamics"
}
},
{
"insert": {
"PART_ID": 2,
"PART_NAME": "Warp Core",
"PRICE": "11000",
"VENDOR_ID": 3,
"VENDOR_NAME": "DarkMatter Devices"
}
},
]
}
This output contains an array of insert and delete commands that describe an update
to the view in terms of records that are no longer present and must be deleted
and new records to be added to the view. The new version of the view can be
constructed by applying these changes to its previous snapshot.
Thus, Feldera does not output the complete view, but only the set of changes to the previous version of the view. As more input changes arrive, Feldera computes additional output updates on top of all previous updates (give it a try!).
This reflects the internal workings of Feldera: instead of reevaluating the query from scratch on every new input, it only updates affected outputs by propagating input changes through the query execution plan. We refer to this as incremental query evaluation. See our paper for a rigorous description of this technique.
Takeaways
Let us review what we have learned in this part of the tutorial:
Feldera operates on changes: a Feldera pipeline transforms a stream of input changes to SQL tables into a stream of output changes to SQL views.
One way to send input changes to a pipeline and consume output changes from it is using HTTP.
Internally, Feldera also works with changes: the Feldera query engine employs incremental algorithms to compute only what has changed in each view without requiring a full re-computation.