The Feldera Blog
An unbounded stream of technical articles from the Feldera team
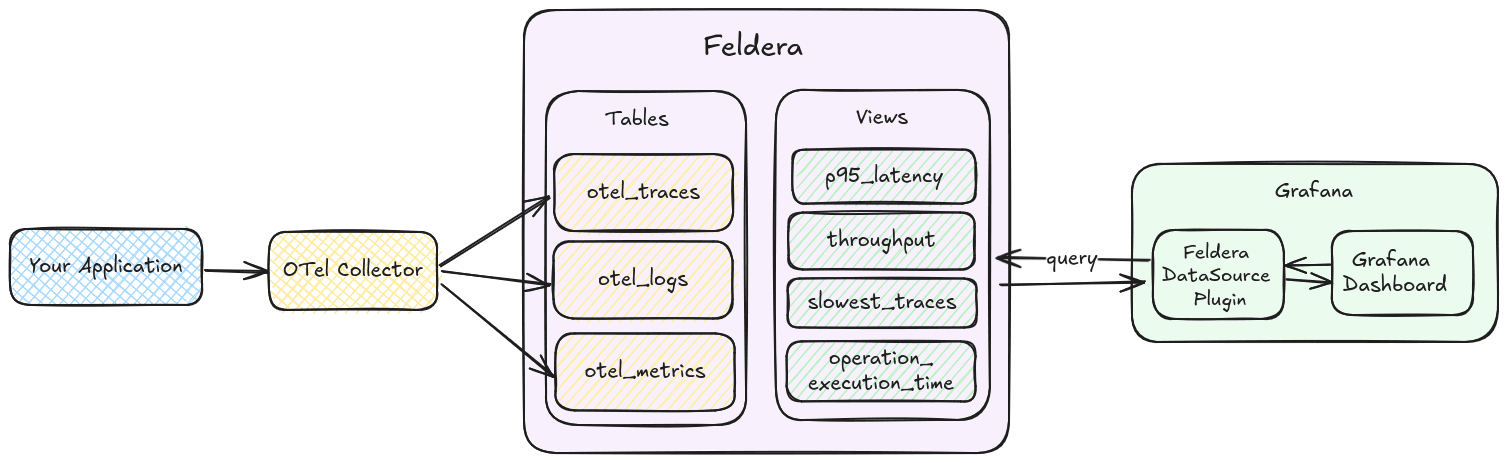
From Traces to Insights: How to Analyze OpenTelemetry Data in Real-Time with SQL
Analyzing OpenTelemetry data to generate insightful visualizations using Feldera.

Incremental Update 17
Performance is paramount in v0.37.

Announcing S3-backed Pipelines
S3-backed pipelines allow your incremental compute tasks to use zero disks and scale far beyond typical local storage sizes.
Incremental Update 16
For massive scale. A quick overview of what's new in v0.36.
Incremental Update 15
A quick overview of what's new in v0.35.
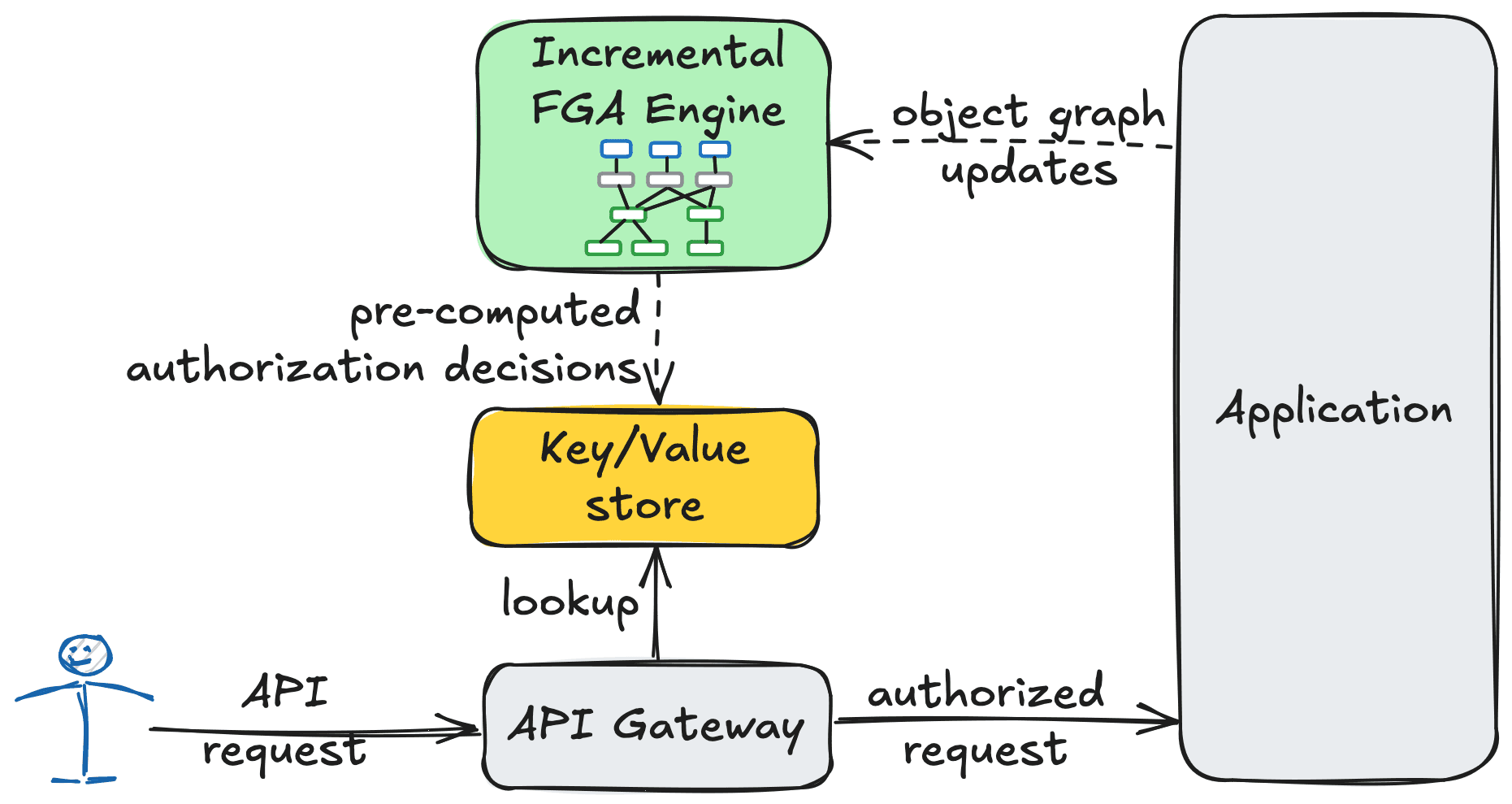
Solving Fine-Grained Authorization by Turning the Problem on its Head
Build a high-performance policy engine with only a few lines of SQL.
Incremental Update 14
A quick overview of what's new in v0.34.
Incremental Update 13
Iceberg! A quick overview of what's new in v0.33.

Reflecting on a Year of Innovation and Looking Ahead
Reflecting on 2024 and a sneak peak into our scalability goals for 2025.