In most analytics systems, the bigger your dataset, the bigger your compute costs. Even if only a sliver of your data changes from one moment to the next. That’s because batch engines reprocess everything, every time you want to derive fresh insights from your data.
If you run a query against a 10TB dataset in Spark, Databricks, Snowflake, or any database the system churns through all 10TB. If a second later you reissue the same query, these systems will again churn through the entire 10TB, even if as little as only a single row might have changed since the last time you ran the query!
This leads to a key inefficiency. The size of the cluster to evaluate the query depends on the size of the dataset. We see customers operate massive clusters that do nothing but run the same corpus of queries 24x7 to turn new data into insights. Even when 99.9999% of the data is identical between runs as your data evolves over time (that is, the data sources receive new inserts, updates and deletes over time).
The result for your business?
- Your compute spend and operational costs are completely out of sync with the business value you’re deriving from it.
- Your cloud bill explodes with compute hours.
- Your data engineering team works overtime to craft fragile, brittle workarounds to avoid this recomputation cost, not realizing that they are in fact in build-your-own database engine territory. They celebrate a 10% saving on the cloud bill after spending 3 orders of magnitude more in engineering salaries to achieve it.
- Meanwhile, your warehouse vendor and their sales team laugh their way to the bank, as their compute-based pricing doesn’t care that you’re recomputing almost exactly the same results from scratch each time.
An old problem with no good solutions (until now)
This is the incremental computing problem, one that has been around for decades and many have tried to solve it (see section 10 in our extended paper for a literature review).
Most teams tackle this via custom batch pipelines that periodically recompute results -- essentially hand-coded engines -- because batch systems remain unmatched in usability and correctness. This approach however suffers from marginal returns for massive sunk costs as I mentioned above.
The alternatives just haven’t measured up for complex workloads at scale. For example, stream processors like Flink or Spark Streaming often sacrifice correctness and require deep distributed systems expertise. Materialized views in systems like Databricks, Snowflake, or Clickhouse fall back to manual refreshes or full recomputations, with very limited support for incremental refreshes.
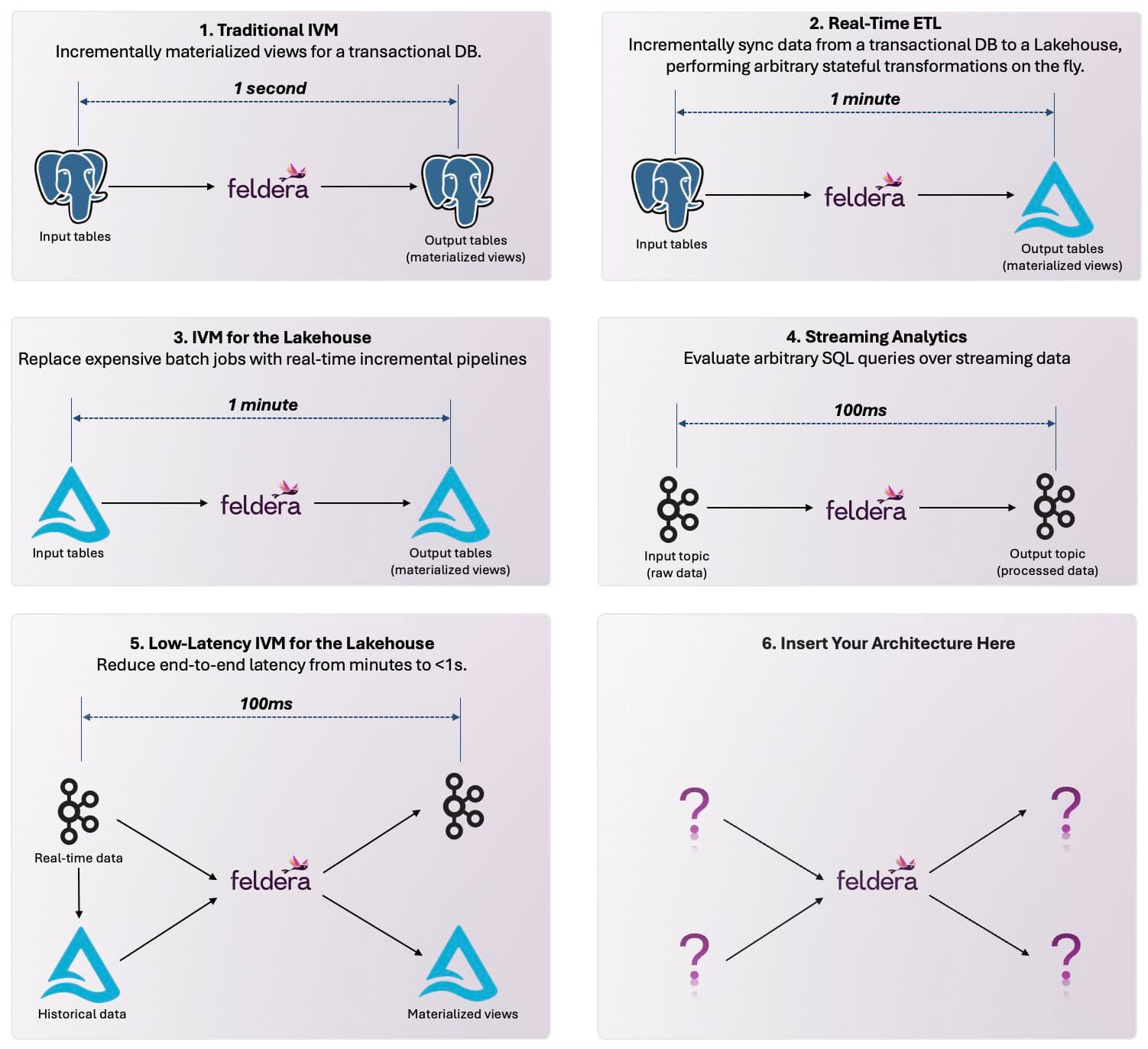
Feldera broke this 50-year barrier by proving that just four mathematical operators are enough to express any SQL query as an incremental computation — so you can run the same SQL you write today, but incrementally, automatically, and with full correctness.
True Incremental Compute Changes The Economics of Analytics
Feldera’s incremental computation engine flips the data analytics cost model from before.
- Data teams port their warehouse SQL as-is; tables and deeply nested views with hundreds of joins, distincts, unions, aggregations and even recursive queries. They start these Feldera pipelines which connect to your existing live and/or historical data sources and destinations.
- The pipelines automatically detect how your input data changes, and by only looking at the input changes, incrementally updates only the rows in views that need to be changed.
The impact: Even if you maintain tens of terabytes of state in Feldera, the compute you run -- and therefore your cloud bill -- is proportional to the size of the change, not the total size of the data set. This is in fact a hard mathematical guarantee in Feldera: the compute work a pipeline does is proportional to the size of the change (O(delta)), not the size of the dataset (O(N)).

A case study
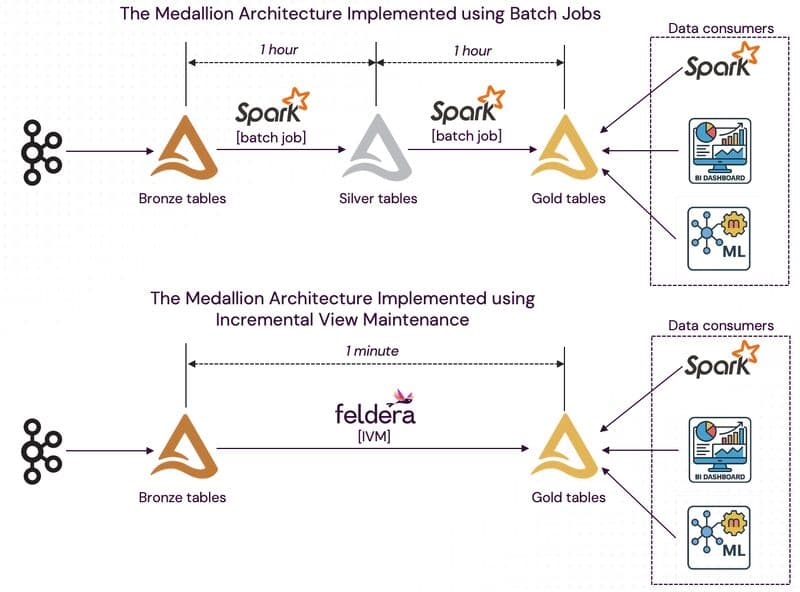
One of our enterprise customers was running a medallion architecture using Spark, running complex queries 24x7 to keep the gold layer fresh. Running hundreds of thousands of lines of complex SQL queries and keeping compute costs down proved to be a challenge, given the 70 node Spark cluster that needed to be on all the time. Freshness was at least an hour delayed. The team tried several solutions to improve freshness and keep costs low, and realized that vendor marketing was light years ahead of the actual technologies, until they reached out to Feldera.
With Feldera, the team rapidly migrated hundreds of thousands of lines of SQL to Feldera (a story we’ll share later) and hooked into the exact same source and destination Delta Tables as before. Post-backfill, all their pipelines were running on one or two compute nodes overall, that update views *in milliseconds* as the input data evolves. For context, some of these pipelines had up to 10K lines of SQL over many dozens of tables and views with hundreds of joins, aggregates, unions, distincts, deeply nested subqueries and more – and yet, Feldera updates them in real-time without any handholding. And the best part: it’s the exact same SQL and semantics they were running before, computing the same row-by-row results as their current batch analytics stack.
This is the true power of incremental compute. By only needing compute resources proportional to the size of the change, instead of the size of the whole dataset, businesses can dramatically slash compute spend for their analytics.
Is your business bleeding cloud spend for analytics?
If so, book a deep dive with our engineering team to stem the wound.