One of the biggest advantages of open table formats like Delta Lake and Apache Iceberg is that you can query the same data with multiple engines. No vendor lock-in, just pick the best tool for each job.
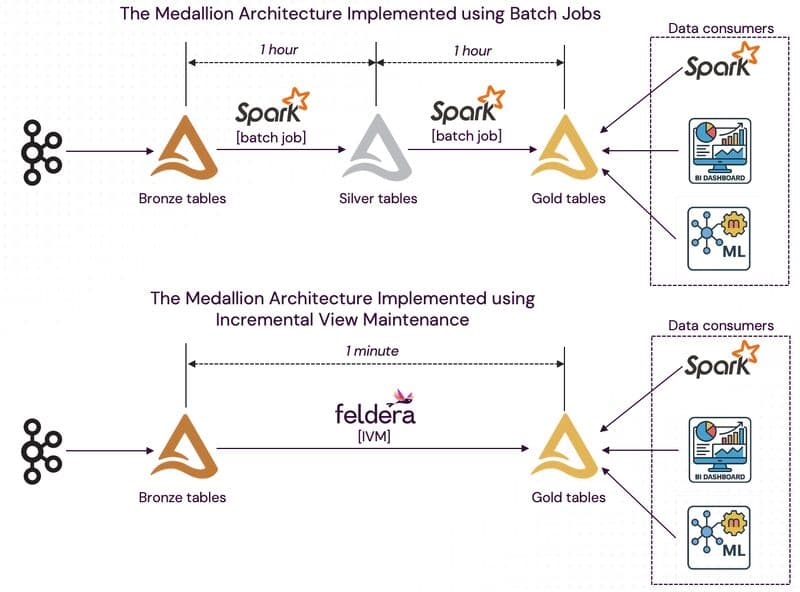
Case in point: We’re working with a customer who built their Medallion architecture using Apache Spark and Delta Lake. But as their business evolved, so did user expectations—especially around latency. Spark’s batch processing couldn’t keep up with the demand for fresh insights.
The solution? We replaced periodic Spark jobs with the Feldera Incremental View Maintenance (IVM) engine. Feldera picks up changes to lower-tier tables and updates higher-tier tables in real-time, reducing the end-to-end latency of the pipeline from hours to minutes.
Prior to open table formats, in the world of legacy databases, such a migration would require completely re-architecting the entire data stack in order to use a new query engine. But thanks to the use of Delta Lake, the transition was completely seamless to the rest of the company:
✅ The data hasn't moved and can be read using Spark, Trino, etc., just like before the migration.
✅ Same ingestion pipeline from Kafka to the Bronze layer.
✅ Existing BI dashboards reading the Gold layer stayed untouched—only now they show near-real-time data!
Want to see how it works?
Watch Gerd Zellweger's webinar on replacing batch analytics with Feldera.
Toward Real-Time Medallion Architecture

Leonid RyzhykCTO / Co-Founder


Other articles you may like

Database computations on Z-sets
How can Z-sets be used to implement database computations

Implementing Batch Processes with Feldera
Feldera turns time-consuming database batch jobs into fast incremental updates.

Feldera: three tools for the price of one
Feldera is not just a database engine. Feldera SQL is in some respects substantially more powerful than standard SQL, enabling new use cases.