
Incremental View Maintenance is a paradoxical concept: it's lived in the database community’s collective conscience for decades, yet has never fully materialized as a feature in any modern DB.
But wait—don't we have IVM systems like pg_ivm, Spark Streaming, and Snowflake Dynamic Tables? Sure, but these are all partial solutions at best. In my view, a complete IVM engine must:
1️⃣ support arbitrary SQL queries
2️⃣ over data of any size
3️⃣ fully incrementally—processing input changes without full recomputation
Such an IVM system would be a massive game changer, as it would replace expensive SQL batch jobs with incrementally materialized views, reducing time to insights from hours to seconds and cutting down infrastructure costs.
No existing system meets that bar—not even close!
That's why we're building the first complete IVM engine at Feldera. We already meet criteria 1️⃣ and 3️⃣. As for 2️⃣, Feldera processes multi-billion-record datasets on a single node in real-time and supports clustered execution of multiple pipelines—replacing massive Spark clusters with a handful of nodes. Our upcoming scale-out capabilities will push performance another order of magnitude forward.
There's a modern twist in the IVM story.
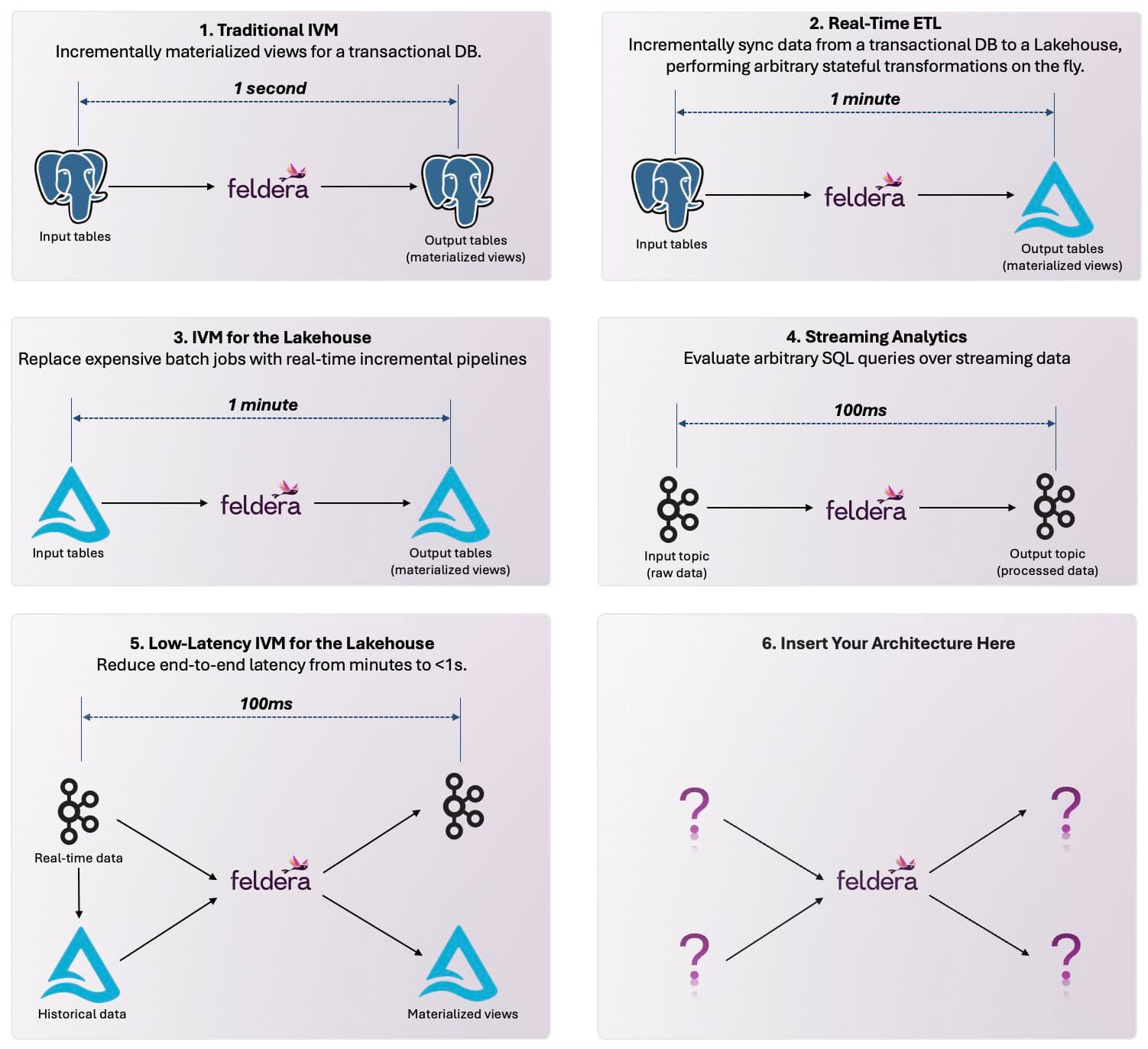
Traditionally, IVM was intended as part of an integrated DBMS. Today, technologies like open table formats, CDC, and Kafka enable a Universal IVM architecture, where a general-purpose IVM engine like Feldera incrementally maintains views over diverse sources, writing results to a variety of destinations.
Universal IVM can power use cases ranging from classic IVM to real-time ETL and streaming analytics.

Here is a visual guide to how Universal IVM will revolutionize your data stack (and we need your help completing it!)
Learn more about these and other use cases here: https://docs.feldera.com/tutorials/
More info:
Replacing batch jobs with IVM: https://docs.feldera.com/use_cases/batch/intro/
Streaming analytics in SQL: https://docs.feldera.com/tutorials/time-series
IVM enables real-time Web apps: https://docs.feldera.com/use_cases/real_time_apps/part1
How Feldera connects to various data sources and sinks: https://docs.feldera.com/connectors/




