
Introduction
In three previous blog posts we have:
introduced Z-sets as a representation for database tables and changes to database tables,
given a simple Java implementation of the basic Z-set operations,
In this blog post we describe two additional SQL operations for
Z-sets: GROUP BY and JOIN.
Recall that a Z-set is just a table where each row has an attached integer weight, which can be either positive or negative.
All the code in this blog post is available in the Feldera repository
in the
org.dbsp.simulator
Java namespace.
GROUP BY
In SQL the operation GROUP BY is always paired with an aggregation.
However, with Z-sets we handle grouping separately. What is the
result produced by GROUP BY? The answer is: a new data structure,
which is not a Z-set. We call this new data structure an indexed
Z-set.
Consider a database table T:
| Name | Age |
|---|---|
| Billy | 28 |
| Barbara | 36 |
| John | 12 |
What happens when we group records in this database by some key? For example, consider the following query fragment:
SELECT ... FROM T GROUP BY LEFT(T.name, 1)
In this query we use as the key for grouping the function
LEFT(T.name, 1), which returns the first character of the name in
each row.
So the first step is to evaluate this key function for each row:
| Name | Age | Key |
|---|---|---|
| Billy | 28 | B |
| Barbara | 36 | B |
| John | 12 | J |
For the first 2 rows the grouping key is B, and for the last row the
key is J.
The next step is to form groups: for each key the group is composed
from all rows that have that key. So for our original table we have
two groups. The B group is a table:
| Name | Age |
|---|---|
| Billy | 28 |
| Barbara | 36 |
And the J group is another table:
| Name | Age |
|---|---|
| John | 12 |
These two tables form a partition of the original table: if we put
them together (using UNION) we get the original table unchanged.
These observations suggest a Java data structure for representing
these groups: a Map<K, Z>, where K is the type of the keys, and
Z is a... table (just a Z-set, really). We call these structures
"indexed Z-sets", because they do work like traditional database
indexes: given a value for the key, they immediately allow us to
retrieve all the records with the corresponding key. The following
diagram shows the indexed Z-set constructed for our example table and
group key:
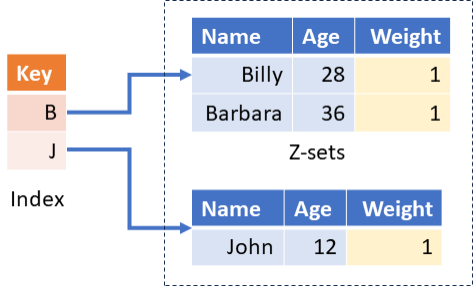
And here is the Java data structure:
public class IndexedZSet<Key, Value, Weight> {
final WeightType<Weight> weightType;
final Map<Key, ZSet<Value, Weight>> index;
public IndexedZSet(WeightType<Weight> weightType) {
index = new HashMap<>();
this.weightType = weightType;
}
public void append(Key key, Value value, Weight weight) {
ZSet<Value, Weight> zset = this.index.getOrDefault(
key, new ZSet<>(this.weightType));
if (zset.isEmpty())
this.index.put(key, zset);
zset.append(value, weight);
if (zset.isEmpty())
this.index.remove(key);
}
public int groupCount() {
return this.index.size();
}
}
Remember to implement proper equals and hashCode methods for the
Key type that you use!
Now we can easily implement the GROUP BY operation. This is just a
new method of the ZSet class which takes as an argument a function
which computes the keys:
public class ZSet<Data, Weight> {
// extending existing class
public <Key> IndexedZSet<Key, Data, Weight> index(Function<Data, Key> key) {
IndexedZSet<Key, Data, Weight> result = new IndexedZSet<>(this.weightType);
for (Map.Entry<Data, Weight> entry: this.data.entrySet()) {
Weight weight = entry.getValue();
Key keyValue = key.apply(entry.getKey());
result.append(keyValue, entry.getKey(), weight);
}
return result;
}
}
We have called our method index, but we could have called it groupBy as well.
We can test it:
@Test
public void testIndex() {
ZSet<Person, Integer> input = getPersons();
IndexedZSet<String, Person, Integer> index = input.index(
p -> p.name != null ? p.name.substring(0, 1) : null);
Assert.assertEquals(2, index.groupCount());
System.out.println(index);
}
Here is the output produced:
{
B=>{
Person{name='Billy', age=28} => 1,
Person{name='Barbara', age=36} => 1
},
J=>{
Person{name='John', age=12} => 1
}
}
The result has the expected structure: for the B key we have a Z-set
with two rows, and for the J key we have a Z-set with 1 row. (We
have omitted the IndexedZSet::toString method implementation, you
can find it online.)
Aggregations applied to groups
We have implemented aggregations on Z-sets in the previous blog
post. The
ZSet::aggregate method had this signature:
public <Result, IntermediateResult> Result
aggregate(AggregateDescription<Result, IntermediateResult, Data, Weight> aggregate);
We have used a helper class AggregateDescription to hold the
information required for computing the aggregation.
In SQL a combination GROUP BY-aggregation logically creates groups
and then immediately applies an aggregation function to each group to
produce a single value for each group. We define aggregation for
Indexed Z-sets as a method of the IndexedZSet class that also takes
as argument an AggregateDescription. The result is another indexed
Z-set, where for each group we produce a Z-set with a single value,
the result of the aggregation, with a weight of one:
public class IndexedZSet<Key, Value, Weight> {
// Extending previously defined class
public <Result, IntermediateResult> IndexedZSet<Key, Result, Weight>
aggregate(AggregateDescription<Result, IntermediateResult, Value, Weight> aggregate) {
IndexedZSet<Key, Result, Weight> result = new IndexedZSet<>(this.weightType);
for (Key key: this.index.keySet()) {
ZSet<Value, Weight> set = this.index.get(key);
Result agg = set.aggregate(aggregate);
result.append(key, agg, this.weightType.one());
}
return result;
}
}
Here is a test case using MAX as the aggregation function. This is
equivalent to the SQL query SELECT LEFT(T.name, 1), MAX(T.age) FROM T
GROUP BY LEFT(T.name, 1):
@Test
public void testIndexAggregate() {
ZSet<Person, Integer> input = getPersons();
IndexedZSet<String, Person, Integer> index = input.index(
p -> p.name != null ? p.name.substring(0, 1) : null);
AggregateDescription<Integer, Integer, Person, Integer> max =
new AggregateDescription<>(0, (a, p, w) -> Math.max(a, p.age), r -> r);
IndexedZSet<String, Integer, Integer> aggregate = index.aggregate(max);
System.out.println(aggregate);
}
The printed output is:
{
B=>{
36 => 1
},
J=>{
12 => 1
}
}
Flattening indexed Z-sets
We have a way to produce indexed Z-sets from Z-sets, but no way to
produce Z-sets from indexed Z-sets. We define a flatten method for
indexed Z-sets for this purpose. Since a Z-set maps values to
weights, we need to supply a function which combines a key and a value
from an indexed Z-Set into a single value for the Z-set:
public class IndexedZSet<Key, Value, Weight> {
// Extending previously defined class
public <Result> ZSet<Result, Weight> flatten(BiFunction<Key, Value, Result> combine) {
ZSet<Result, Weight> result = new ZSet<>(this.weightType);
for (Key key: this.index.keySet()) {
ZSet<Value, Weight> set = this.index.get(key);
ZSet<Result, Weight> map = set.map(v -> combine.apply(key, v));
result.append(map);
}
return result;
}
public ZSet<Value, Weight> deindex() {
return this.flatten((k, v) -> v);
}
}
The method deindex, which is built using flatten, is the inverse
of the index method we have previously defined. Given an indexed
Z-set it returns the original Z-set it was produced from, by
essentially ignoring the keys and concatenating all the rows.
@Test
public void testDeindex() {
ZSet<Person, Integer> input = getPersons();
IndexedZSet<String, Person, Integer> personIndex = input.index(p -> p.name);
ZSet<Person, Integer> flattened = personIndex.deindex();
Assert.assertTrue(input.equals(flattened));
}
We can use the three methods index+aggregate+flatten to produce
the precise equivalent of the SQL GROUP BY followed by aggregation:
@Test
public void testGroupByAggregate() {
ZSet<Person, Integer> input = getPersons();
IndexedZSet<String, Person, Integer> index = input.index(p -> p.name != null ? p.name.substring(0, 1) : null);
AggregateDescription<Integer, Integer, Person, Integer> max =
new AggregateDescription<>(0, (a, p, w) -> Math.max(a, p.age), r -> r);
IndexedZSet<String, Integer, Integer> aggregate = index.aggregate(max);
ZSet<Person, Integer> keyAge = aggregate.flatten(Person::new);
System.out.println(keyAge);
}
The output is the one you would expect:
{
Person{name='J', age=12} => 1,
Person{name='B', age=36} => 1
}
JOIN
Finally, let's implement database joins. More precisely, we will implement equi-joins, which are joins where the join is done based on expressions that require fields in the joined relations to be equal to each other. Joins can also be implemented by using a Cartesian product followed by a filtering operation. But for equi-joins we can do much less work by first indexing both sets to be joined on the common key. Then we only need to consider the matching keys, and not all pairs of elements, which can be much more efficient in practice.
In our implementation equi-join is an operation applied to indexed Z-sets (and not Z-sets) which have the same key type. It receives as argument a function that combines each row from the left collection with a matching row from the right collection. The result is also an indexed Z-set, where for each key we have a result produced from all pairs of matching records:
public class IndexedZSet<Key, Value, Weight> {
// Extending previously defined class
public <Result, OtherValue> IndexedZSet<Key, Result, Weight> join(
IndexedZSet<Key, OtherValue, Weight> other,
BiFunction<Value, OtherValue, Result> combiner) {
IndexedZSet<Key, Result, Weight> result = new IndexedZSet<>(this.weightType);
for (Key key: this.index.keySet()) {
if (other.index.containsKey(key)) {
ZSet<Value, Weight> left = this.index.get(key);
ZSet<OtherValue, Weight> right = other.index.get(key);
ZSet<Result, Weight> product = left.multiply(right, combiner);
result.index.put(key, product);
}
}
return result;
}
}
Notice how the result is produced using the multiply Z-set
operation, which implements the Cartesian
product.
And a test case:
@Test
public void testJoin() {
ZSet<Person, Integer> input = getPersons();
ZSet<Address, Integer> address = getAddress();
IndexedZSet<String, Person, Integer> personIndex = input.filter(
p -> p.name != null).index(p -> p.name);
IndexedZSet<String, Address, Integer> addressIndex = address.filter(
a -> a.name != null).index(a -> a.name);
IndexedZSet<String, PersonAddressAge, Integer> join = personIndex.join(addressIndex,
(p, a) -> new PersonAddressAge(p.name, p.age, a.city));
ZSet<PersonAddressAge, Integer> result = join.deindex();
System.out.println(result);
}
Producing the following output:
{
PersonAddressAge{name='Barbara', age=36, city='Seattle'} => 1,
PersonAddressAge{name='Billy', age=28, city='San Francisco'} => 1,
PersonAddressAge{name='John', age=12, city='New York'} => 1
}
Since the output of join is an IndexedZSet, we have to use the
deindex method to produce a ZSet.
The mathematical structure of indexed Z-sets
In our first blog post about Z-sets we have pointed out that Z-sets form a nice algebraic structure called "commutative group." That means they have nice plus, minus, and zero operations, which behave similarly to numbers (i.e., plus is commutative and associative, minus is the inverse operation of plus, and zero, which is the neutral element for addition).
This happens because the type Map<A, B> "inherits" the algebraic
structure from the type B. Z-sets have B as integers, and because
integers form a commutative group, Z-sets also form a commutative
group.
If you break them down, indexed Z-sets are in fact Map<K, Z>, where
Z is a Z-set type. But, as we pointed out, Z-sets form a
commutative group, and thus it follows that indexed Z-sets themselves
form a commutative group! We haven't implemented the plus, minus, and
zero operations for indexed Z-sets, but they would be very easy to
write down. However, this property is actually crucial for
incremental computation. This will allow us to efficiently
(incrementally) evaluate all queries that compute on either Z-sets or
indexed Z-sets.
Conclusions
We have introduced Indexed Z-sets, which are a form of nested
relations: a relation where each "row" is itself a relation. SQL does
not support computations on nested relations -- they can only be
created temporarily using GROUP BY (or other equivalent statements
such as OVER), but each nested collection has to be immediately
reduced to a single value using aggregation. Indexed Z-sets could be
extended to arbirary depths (Map<K0, Map<K1, Map<K2, ...>>>), if
desired, but for implementing SQL one level is enough.
So far we have sketched how standard SQL constructs can be implemented
using Z-sets. There are other aspect of SQL we haven't discussed,
such as NULL values, and the behavior of aggregates for empty
collections. More interesting is how we can use Z-sets to compute not
just SQL queries, but how to update the results of SQL queries
incrementally when the input collections change. That will be the
subject of future blog posts.