JSON Format
Feldera can ingest and output data in the JSON format
Here we document the JSON format supported by Feldera. The specification consists of four parts:
- Encoding invividual table rows. Describes
JSON encoding of an individual row in a SQL table or view, e.g.:
{"part": 1, "vendor": 2, "price": 10000} - Encoding data change events.
A data change event represents an insertion, deletion, or modification
of a single row, e.g.:
{"insert": {"part": 1, "vendor": 2, "price": 30000}} - Encoding multiple changes. Describes JSON
encoding of a stream of data change events, e.g.:
{"delete": {"part": 1, "vendor": 2, "price": 10000}}
{"insert": {"part": 1, "vendor": 2, "price": 30000}}
{"insert": {"part": 2, "vendor": 3, "price": 34000}} - Configuring JSON event streams. Describes how the user can specify the JSON format for a stream of events when sending and receiving data via connectors or over HTTP.
Encoding individual rows
A row in a SQL table or view is encoded as a JSON object whose keys match
the names of the columns in the table. Keys can occur in an arbitrary order.
Column names are case-insensitive, except for columns whose names are declared
in double quotes (e.g., create table foo("col")). NULLs are encoded
as JSON null values or by simply omitting the columns whose value is NULL.
For example, given the following table declaration
create table json_test (
b BOOLEAN,
i INTEGER,
d DOUBLE,
v VARCHAR(32),
cc CHAR(16),
t TIME,
ts TIMESTAMP,
dt DATE,
ar BIGINT ARRAY
);
the JSON encoding of a row would look like this:
{
"B":true,
"I":-1625240816,
"D":0.7879946935782574,
"V":"quod",
"CC":"voluptatem",
"T":"05:05:24",
"TS":"2023-11-21 23:19:09",
"DT":"2495-03-07",
"AR":[1,2,3,4,5]
}
Types
| Type | Example |
|---|---|
| BOOLEAN | true, false |
| TINYINT,SMALLINT, INTEGER, BIGINT | 1, -9 |
| FLOAT, DOUBLE, DECIMAL | -1.40, "-1.40", 12.53, "12.53", 1e20, "1e20" |
| VARCHAR, CHAR, STRING | abc |
| TIME | 12:12:33, 23:59:29.483, 23:59:09.483221092 |
| TIMESTAMP | 2024-02-25 12:12:33 |
| DATE | 2024-02-25 |
| BIGINT ARRAY | [1, 2] |
| VARCHAR ARRAY ARRAY | [[ 'abc', '123'], ['c', 'sql']] |
BOOLEAN
The accepted values are true or false.
Integers (TINYINT, SMALLINT, INTEGER, BIGINT)
Must be a valid integer and fit the range of the type (see SQL Types), otherwise an error is returned on ingress.
Decimals (DECIMAL / NUMERIC)
Both the scientific notation (e.g., 3e234) and standard floating point numbers
(1.23) are valid. The parser will accept decimals formatted as JSON numbers
(1.234) or strings ("1.234"). The latter representation is more robust as it
avoids loss of precision during parsing (the Rust JSON parser we use represents all
fractional numbers as 64-bit floating point numbers internally, which can cause loss
of precision for decimal numbers that cannot be accurately represented in that way).
Floating point numbers (FLOAT, DOUBLE)
Both the scientific notation (e.g., 3e234) and standard floating point numbers
(1.23) are valid.
NaN, Inf, and -Inf floating point values are currently not supported by
the JSON parser and encoder.
Strings (CHAR, VARCHAR, STRING, TEXT)
SQL strings are encoded as JSON strings.
The JSON parser does not currently enforce limits on the number of characters in a string. Strings that exceed the length specified in the SQL table declaration are ingested without truncation.
TIME
Specifies times using the HH:MM:SS.fffffffff format where:
HHis hours from00-23.MMis minutes from00-59.SSis seconds from00-59.fffffffffis the sub-second precision up to 9 digits from0to999999999
A leading 0 can be skipped in hours, minutes and seconds. Specifying the subsecond precision is optional and can have any number of digits from 0 to 9. Leading and trailing whitespaces are ignored.
DATE
Specifies dates using the YYYY-MM-DD format.
YYYYis the year from0001-9999MMis the month from01-12DDis the day from01-31
Invalid dates (e.g., 1997-02-29) are rejected with an error during ingress.
Leading zeros are skipped, e.g., 0001-1-01, 1-1-1, 0000-1-1 are all
equal and valid. Leading and trailing whitespaces are ignored.
TIMESTAMP
Specifies dates using the YYYY-MM-DD HH:MM:SS.fff format.
YYYYis the year from0001-9999MMis the month from01-12DDis the day from01-31HHis hours from00-23.MMis minutes from00-59.SSis seconds from00-59.fffis the sub-second precision up to 3 digits from0to999
Note that the same rules as specified in the Date and Time sections apply, except that the sub-second precision is limited to three digits (microseconds). Specifying more digits for the subsecond precision on ingress will trim the fraction to microseconds. Leading and trailing whitespaces are ignored.
ARRAY
Arrays are encoded as JSON arrays.
Encoding data change events
Feldera operates over streams of data change events. A data change event represents an insertion, deletion, or modification of a single row in a SQL table or view. We currently support two data change event formats in JSON: (1) the raw format and (2) the insert/delete format.
The insert/delete format
A data change event in this format is represented as a JSON object with a
single key, which must be equal to insert or delete. The associated value
represents the table row to be inserted or deleted, encoded using the format
documented above. Example row insertion event:
{"insert": {"part": 1, "vendor": 2, "price": 30000}}
Example row deletion event:
{"delete": {"part": 1, "vendor": 2, "price": 10000}}
The raw format
This format is applicable to append-only event streams where rows can only be inserted but not deleted. In this case, a data change event can be represented as a SQL record without any additional framing, with the insert operation being implied, e.g., the following data change event in the raw format
{"part": 1, "vendor": 2, "price": 30000}
is equivalent to
{"insert": {"part": 1, "vendor": 2, "price": 30000}}
Encoding multiple changes
Data change events are exchanged as data streams transmitted over transports such as HTTP or Kafka. We use newline-delimited JSON (NDJSON) to assemble individual data change events into a stream. In NDJSON, each line within the data stream represents a self-contained and valid JSON document, in this case, a data change event:
{"delete": {"part": 1, "vendor": 2, "price": 10000}}
{"insert": {"part": 1, "vendor": 2, "price": 30000}}
{"insert": {"part": 2, "vendor": 3, "price": 34000}}
...
A stream of data change events can be configured to combine multiple events into JSON arrays. This format still uses NDJSON, where each line contains an array of data change events:
[{"delete": {"part": 1, "vendor": 2, "price": 10000}}, {"insert": {"part": 1, "vendor": 2, "price": 30000}}]
[{"insert": {"part": 2, "vendor": 3, "price": 34000}}, {"delete": {"part": 3, "vendor": 1, "price": 5000}}]
...
This format allows one to break up the event stream into transport messages so that each message contains a valid JSON document by encoding all events in the message as an array.
Configuring JSON event streams
Configure connectors via the Feldera Web Console
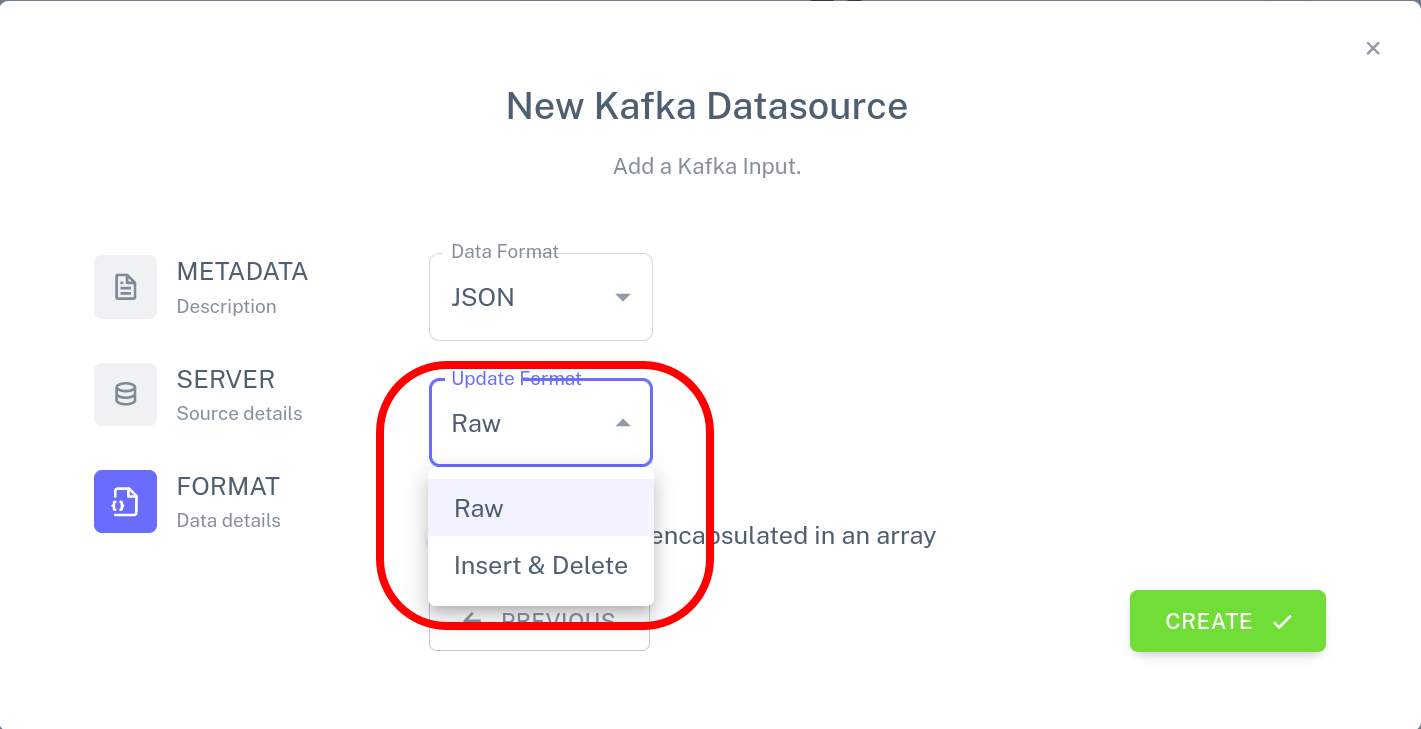
When creating a new input or output connector using the Feldera Web Console,
the data format is configured in the FORMAT section of the connector
creation wizard:
- choose
JSONfrom the list of supported formats - choose appropriate data change event encoding (
RaworInsert & Delete) - enable array encapsulation if the stream contains events grouped in arrays
See also the input/output connector tutorial.
Configure connectors via the REST API
When creating or modifying connectors via the REST API
/connectors endpoint,
the data format is specified in the format field of
the connector configuration:
{
"transport": {
"name": "url_input",
"config": {
"path":"https://feldera-basics-tutorial.s3.amazonaws.com/part.json"
}
},
"format": {
// Choose JSON format for the connector.
"name": "json",
"config": {
// Choose data change event format for this connector.
// Supported values are `insert_delete` and `raw`.
"update_format": "insert_delete",
// Disable array encoding.
"array": false
}
},
"max_queued_records":1000000
}
Streaming JSON over HTTP
When sending data to a pipeline over HTTP via the /ingress
API endpoint, the data format is specified as part of the URL, e.g.:
# `?format=json` - Chooses JSON format for the stream.
# `&update_format=insert_delete` - Specifies data change event format. Supported values are `insert_delete` and `raw`.
# `&array=false` - Don't use array encoding.
curl -X 'POST' 'http://localhost:8080/v0/pipelines/018a67a5-32e8-7e23-825d-a8a64872ab7c/ingress/PART?format=json&update_format=insert_delete&array=false' -d '
{"insert": {"id": 1, "name": "Flux Capacitor"}}
{"insert": {"id": 2, "name": "Warp Core"}}
{"insert": {"id": 3, "name": "Kyber Crystal"}}'
When receiving data from a pipeline over HTTP via the
/egress
API endpoint, we currently only support the insert/delete data change event
format with array encapsulation. Specify ?format=json in the URL
to choose this encoding for output data.
curl -s -N -X 'POST' http://localhost:8080/v0/pipelines/018a67a5-32e8-7e23-825d-a8a64872ab7c/egress/PREFERRED_VENDOR?format=json
See also the HTTP input and output tutorial.