
When it comes to real-time fraud detection, feature freshness is key to prediction accuracy. This means that you want to compute features over the latest transactions and use these features to flag the transactions as fraudulent or not, because trust me, fraudsters aren't going to wait for your data systems to catch up.
Today, we'll cover a unique capability in Feldera that is essential for achieving perfect feature freshness, the rolling aggregate operator. Like all other SQL operators we support, Feldera evaluates rolling aggregates efficiently and fully incrementally on both batch and streaming data. To the best of our knowledge, no other engine can do that.
In this blog, we will:
- Introduce rolling aggregates
- Discuss why rolling aggregation is challenging to implement for many streaming engines
- Outline how we solve the problem in Feldera
Rolling aggregates
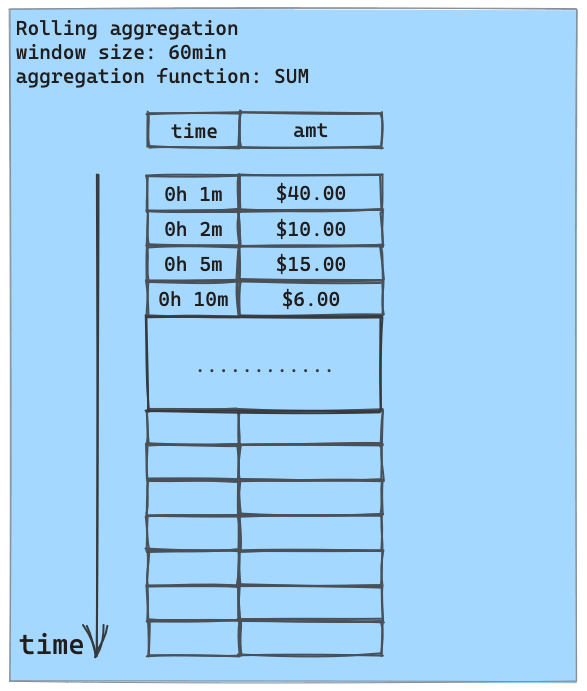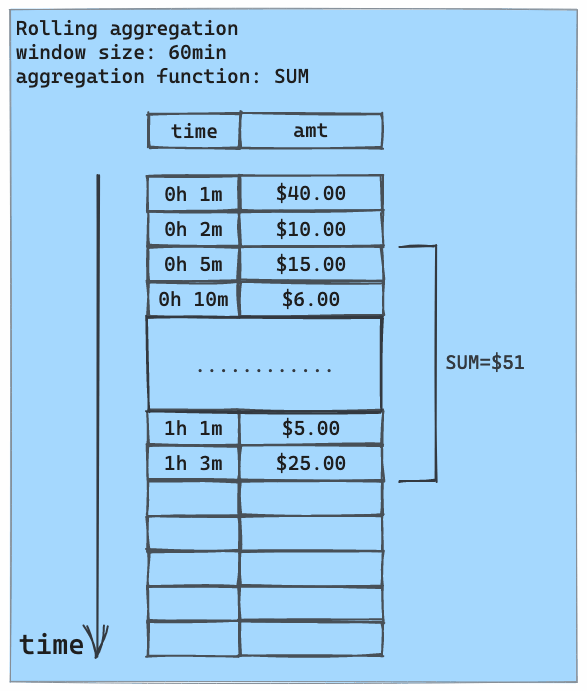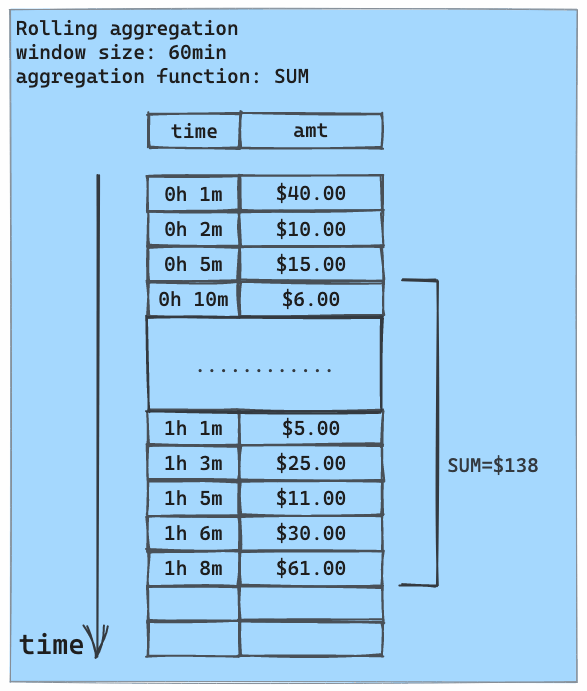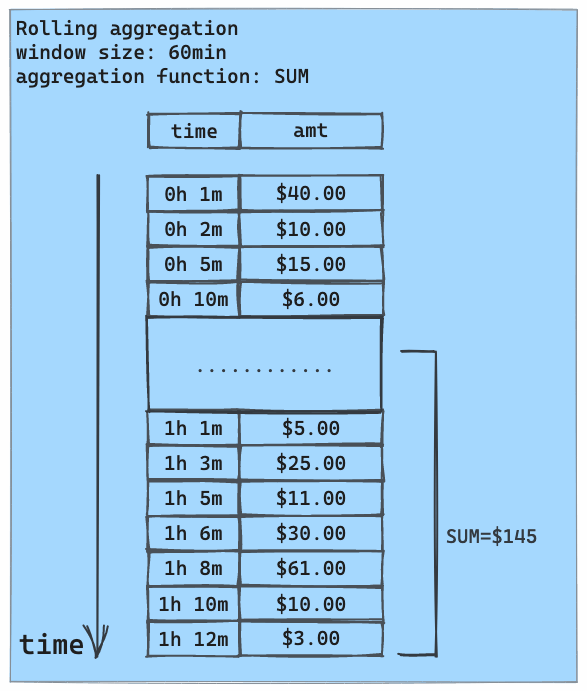
Rolling aggregation is typically used with time series data. For each data point in a time series, it computes an aggregate (e.g., count, sum, average, standard deviation, etc.) over a fixed time frame (such as a day, an hour, or a month) preceding this data point. This aggregate summarizes the entire recent event history into a single value. This summary, provided as a feature to the ML model along with raw time series data, helps the model to detect anomalous behaviors.
The following animation illustrates rolling aggregation using the SUM aggregate and a 1-hour rolling window:

Rolling aggregates can be expressed in ANSI SQL using the OVER clause:
-- Credit card transactions.
CREATE TABLE TRANSACTION (
ts BIGINT LATENESS 600, -- UNIX timestamp in seconds
cc_num BIGINT, -- Credit card number
amt DOUBLE -- Transaction amount
);
CREATE VIEW FEATURES AS
SELECT
*,
SUM(amt) OVER window_1_hour
FROM TRANSACTION
WINDOW
window_1_hour AS (PARTITION BY transaction.cc_num ORDER BY ts RANGE BETWEEN 3600 PRECEDING AND CURRENT ROW);The FEATURES view transforms raw records from the TRANSACTION table into feature vectors, including all columns from the table plus a rolling SUM aggregate over a 1-hour window. Let's break it down:
- The
WINDOWclause - Defines a named rolling window that can be used to compute one or more rolling aggregates. PARTITION BY transaction.cc_num- Divides the input table into disjoint partitions, one for each credit card number. Each partition is processed independently.ORDER BY ts- Identifies the timestamp column that imposes logical ordering on rows within each partition.RANGE BETWEEN 3600 PRECEDING AND CURRENT ROW- Specifies the range of timestamps included in the rolling window. In this example, the range includes all events between 1 hour before the current row and the current row itself (inclusive).SUM(amt) OVER window_1_hour- Specifies the aggregate function to compute for each window.
Rolling aggregates and feature freshness
When evaluating the rolling aggregate operator, there are as many individual windows, and hence as many aggregates to compute, as there are data points in the stream! Is this overkill? Can't we compute an aggregate, say, every 5 minutes, and use this value for the next 5 minutes, until an updated aggregate becomes available? This is exactly how hopping window aggregation works:

The trouble is, hopping windows do not account for the data received since the window was last updated. This most recent data tends to have the strongest impact on model accuracy. Incorporating it in feature computation is crucial to achieving high-quality predictions. This property, known as feature freshness is particularly important in fraud detection:
- The most recent non-fraudulent user activity is the most useful for recognizing valid future behaviors.
- Once the fraudster gains access to a user account, they try to exploit it quickly; therefore incorporating the most recent history in feature computation is necessary to minimize the impact of fraud.
Rolling aggregates over streaming data
Rolling aggregates are so immensely useful that ML scientists often include dozens of such aggregates in each of their training pipelines. Luckily, modern SQL databases are good at evaluating these queries over batch data.
Things become less rosy when deploying the trained model in production for real-time inference. The same queries must now be evaluated over streaming inputs. However, most modern streaming query engines either don't support rolling aggregates or make them prohibitively expensive. Why is that? We already know that rolling aggregates require computing a separate aggregate for each input timestamp. Out-of-order data further amplifies the problem. When the system receives a delayed input row, it must not only compute the aggregate for the new row, but also re-evaluate the aggregates for all affected timestamps.

A common workaround is to replace rolling windows with simpler aggregates, such as hopping windows. But as we already know this hurts feature freshness, reducing model accuracy.
Rolling aggregates in Feldera
Feldera supports rolling aggregates on streaming data without compromising on either performance or accuracy. Like with all other SQL constructs, we offer:
✅ Unified batch and stream processing. Feldera can evaluate any SQL query, including OVER, on both batch and streaming inputs. As a result, you can define features once and use them for both model training and inference.
✅ Zero feature skew. Given the same input data, Feldera produces identical outputs, whether the data is ingested as a batch or a stream.
✅ Perfect feature freshness. At any point in time, rolling aggregates produced by Feldera take into account all data points received so far. Upon receiving new time series events, including out-of-order events, Feldera updates output feature vectors within milliseconds.
In order to achieve this, our implementation of rolling aggregates uses an auxiliary radix tree data structure, which allows computing new and updated rolling aggregates incrementally, i.e., by doing work proportional to the size of the changes rather than the size of the entire time series. We plan to dedicate a separate blog to this important data structure. In the meantime you can find its description in the source code.
In our preliminary performance evaluation, Feldera is able to compute multiple rolling aggregates over multiple time windows at a rate of 1 million events per second on a single computer. We are collaborating with our friends at Hopsworks to develop a benchmark for rolling aggregation. We will publish it along with official result once it is finalized.
Takeaways
🔧 Rolling aggregates are a powerful tool when applying machine learning to time series data, especially in use cases that require near-perfect feature freshness, such as real-time fraud detection.
⚖️ It may be tempting to replace rolling aggregates with cheaper operators, such as hopping window aggregates, but in doing so you will be hurting the accuracy of your ML model by sacrificing feature freshnesss.
🚀 With Feldera, you do not need to compromise: we provide full support for rolling aggregation over batch and streaming data, delivering perfect feature freshness and zero online/offline skew while maintaining high throughput even on a single node.
-----
In the next blog of the feature engineering series, we will explore another crucial category of ML features—data enrichment—and demonstrate how these features can be efficiently implemented in Feldera using the asof-join operator.




