
Real-time feature engineering is among the most important applications of streaming analytics today. It comes up in the majority of our customer interactions as a key enabler of ML applications across various domains, from fraud detection and online ads to IoT fleet management. It is also one of the most challenging streaming analytics use cases that requires running complex queries over large volumes of data in both real-time and batch modes.
Feldera's incremental query engine is uniquely suited for such use cases, where other streaming analytics technologies fall short. In this series of blog posts, we will explain the real-time feature engineering problem and show how Feldera enables anyone with basic knowledge of SQL to build real-time feature pipelines.
In this post, we kick off the series by introducing feature engineering and outlining the challenges users face in building real-time feature pipelines today.
Introduction
Feature engineering is the process of transforming raw data into features that better represent the underlying problem to an ML model. While raw data typically represents individual events such as device sensor readings, features summarize many raw events, e.g., average readings collected over a period of time. In practice, features are usually expressed as queries over raw data, stored in a database or data lake.
When raw input data arrives continuously in real-time, feature computation must also be performed in real-time in order to supply the ML model with up-to-date inputs. For instance, predicting an IoT device failure requires analyzing its latest readings with the latency of a few seconds. Another classic example is predicting that a user is about to abandon their online shopping cart, which requires looking at their most recent clickstream events.
Building real-time feature pipelines is notoriously hard. Today's tools of choice such as Flink and Spark Structured Streaming are complex to program, tune, debug, and scale. Operating them requires specialized data engineering and platform teams. This is in stark contrast with traditional batch-oriented pipelines that can compute complex features at scale with a few lines of SQL or PySpark code per feature. As a result, deploying a real-time ML pipeline today requires 10x the time and resources compared to batch-mode ML.
A brief introduction to feature engineering by example
Let's start with a classic ML application: identifying fraudulent credit card transactions. Input data in this application is a real-time stream of transactions. Each transaction has several attributes: card number, purchase time, vendor, amount, etc. These attributes can be used to train an ML model to spot fraud. However this is unlikely to work well since they do not carry sufficient context to distinguish a fraudulent transaction. Intuitively, we are looking for unusual transactions. But any transaction in isolation cannot be judged reliably. We need to augment the data with additional attributes, or features, derived based on the past transaction history. Some potentially useful features include:
- average spending per transaction in the past month
- number of transactions made with this credit card in the last 24 hours
- count of transactions within a 5-mile radius over the past month
Can you think of other useful features? Should we factor in the spending category (grocery, gas, entertainment, etc.)? Does it make sense to group and aggregate transactions per day of week? These are the type of questions an ML engineer must answer as part of their job. Selecting the right features is key to maximizing prediction accuracy. To this end, the ML engineer runs multiple experiments, training and testing many models.
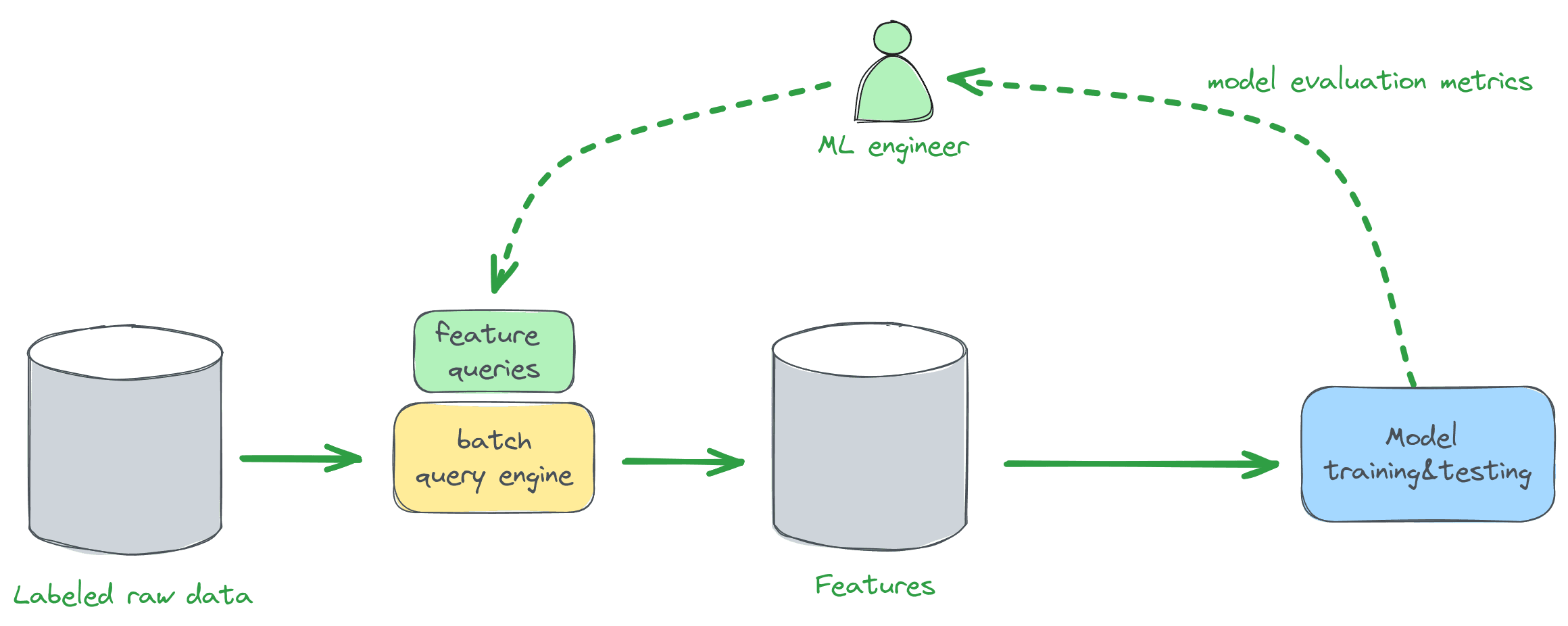
The training workflow is depicted in the diagram below. Raw input data with labels ("fraud"/"not fraud") is collected over time, typically in a data lake or data warehouse. This data is then transformed and aggregated into feature vectors, which are provided as inputs to model training and testing. The ML engineer repeats this process using different combinations of features until reaching the desired prediction accuracy.

In practice, feature queries are written in SQL or Python (using PySpark or a similar framework) and are evaluated in batch mode. Here is an example SQL table declaration that describes raw credit card transaction data and an SQL query that computes several of the features listed above:
-- Raw input data with labels: credit card transactions.
CREATE TABLE transactions (
trans_time TIMESTAMP NOT NULL,
cc_num NUMERIC NOT NULL,
merchant STRING,
category STRING,
amt FLOAT64,
trans_num STRING,
merch_lat FLOAT64 NOT NULL,
merch_long FLOAT64 NOT NULL,
-- Label used for model training and testing.
is_fraud INTEGER
);
-- Enrich raw input data with statistics computed over historical data.
-- These statistics, also known as features, are supplied to the ML model
-- for training and inference.
SELECT
*,
-- Average spending per transaction over a 7-day timeframe.
AVG(amt) OVER(
PARTITION BY cc_num
ORDER BY trans_time
RANGE BETWEEN EXTRACT(EPOCH FROM INTERVAL '7' DAYS) PRECEDING AND 1 PRECEDING) AS
avg_spend_pw,
-- Average spending per transaction over a 30-day timeframe.
AVG(amt) OVER(
PARTITION BY cc_num
ORDER BY trans_time
RANGE BETWEEN EXTRACT(EPOCH FROM INTERVAL '30' DAYS) PRECEDING AND 1 PRECEDING) AS
avg_spend_pm,
-- The number of transactions performed with this credit card over the last 24 hours.
COUNT(*) OVER(
PARTITION BY cc_num
ORDER BY trans_time
RANGE BETWEEN EXTRACT(EPOCH FROM INTERVAL '1' DAYS) PRECEDING AND 1 PRECEDING ) AS
trans_freq_24,
FROM
transactions;The next step is to deploy the model in production. The production pipeline, shown below, ingests raw input data, often from a message queue like Kafka. The ingested data is processed to compute new or updated feature vectors, which become available for lookup during inference.

Unlike the training pipeline, which runs in batch mode, this pipeline must run with low end-to-end latency to deliver fresh features to the ML model. This means that raw data ingest, feature computation, and feature lookup should all happen in real-time or near-real-time. While real-time data ingest and feature lookup are largely solved problems (we will highlight some of the technologies used to achieve this in upcoming blogs), real-time feature computation presents a major challenge.
Real-time SQL to the rescue. Or is it?
An ideal solution is one that doesn't require any additional work from the user. Since the training and production pipelines evaluate the same features, we would hope to run the same SQL or PySpark code in batch and real-time modes. Natural candidates for enabling this are streaming analytics tools like Flink, ksql, and Spark Structured Streaming. Can we just reuse the feature queries we wrote for model training and get real-time results?
Sadly, no. The true strength of SQL is not its syntax, but the high-level contract it offers to the user: express your question in SQL, and the query engine will compute the answer correctly and efficiently. As a result, anyone who knows SQL can build efficient batch analytics with it.
While modern batch platforms are designed to work out of the box, their streaming counterparts are built as do-it-yourself kits where users have to assemble and tune their streaming pipelines out of low-level primitives. SQL may serve as a glue connecting these primitives, but not every valid SQL query is accepted by the tool and not every accepted program will run reliably or produce accurate results. Some of the caveats include:
- Users often discover that certain constructs or their combinations are rejected by the tool for reasons that can only be understood based on the knowledge of its internals.
- Worse, an accepted query can crash, run out of memory, or run anomalously slow.
- Users need to be involved in low-level state management, including data retention and partitioning, which again requires deep insights into what goes on under the hood.
- Platforms like Structured Streaming support append-only input streams, making it hard to work with datasets where records can be deleted and modified.
- Most streaming analytics systems implement weak consistency models. Simply put, the system only promises to output a correct result after not receiving any new inputs for a sufficiently long (and unspecified) period of time -- not a realistic assumption in a streaming system.
- Finally, these systems introduce a lot of operational complexity and require a sophisticated data team to keep them up and running.
Why not pre-compute features in batch mode?
One way to avoid dealing with the limitations of current streaming analytics engines is to pre-compute features ahead of time in batch mode.
Let's look at the SQL query above. For each credit card transaction, this query computes several aggregates, such as the average spend per transaction in the last 30 days, relative to the time of the transaction, for the given credit card. These aggregates must be computed before running model inference to detect whether the transaction is fraudulent.
What if we instead computed the aggregates once a day, say at midnight, and stored the results, indexed by card number, in a database? Whenever a new transaction arrives, we would perform a database lookup to retrieve the values of the aggregates as of midnight. This way, feature computation can run in batch mode, with only feature lookup performed in real time.
While this approach works in some applications, achieving high prediction accuracy often requires features computed from the most complete recent inputs. For instance, in credit card fraud detection, recent transactions have the greatest impact on the performance of the classifier. Similarly, in clickstream analytics, tha latest user actions are most important for predicting their behavior. As another example, in IoT applications, the system may only have a window of a few seconds to predict device failure based on the latest sensor readings.
Real-time feature engineering with Feldera
In summary, organizations deploying real-time ML pipelines today are stuck between two options: invest in an expensive and unwieldy streaming solution, or settle for a simpler alternative that sacrifices feature freshness and, with it, prediction accuracy.
This binary choice is misleading. The real solution lies in a query engine that can evaluate features over streaming data with low latency, while being as expressive and easy to use as modern batch engines.
Feldera is a real-time SQL engine that we built from scratch with precisely this goal: to evaluate arbitrary SQL queries over streaming data while seamlessly integrating with your lakehouse and batch ecosystem. We achieve this by building on a new mathematical model and algorithmic framework for streaming computation, called DBSP. Check out a series of blog posts by Mihai for an easily digestible introduction to DBSP.
Roadmap
In Part 2 of the series, we demonstrate how you can implement a real-time feature pipeline with Feldera.
Future posts in the series will cover:
- How Feldera integrates with your existing ML infrastucture, including data lakehouses, feature stores, and Python frameworks.
- How we solve the dreaded backfill problem, effectively combining streaming and batch analytics within the same engine.




