
About Apache Calcite
The SQL compiler that is part of the Feldera repository is built on top of the Apache Calcite infrastructure. Using Calcite enabled us to create a SQL compiler covering the core SQL language in a record time (we're still working on it, though).
The first lines of code in Calcite were written 20 years ago, by Julian Hyde, which makes Calcite one of the oldest open-source continuously-developed projects (although the project has changed names a few times, the current name "Calcite" is a bit more recent). Julian is still an active contributor to the project.
Calcite is written in Java. Calcite is composed from many parts. These parts are relatively modular and independent, and can be combined in various ways to build various SQL program compilers, analyzers, optimizers, and source-to-source translators. Calcite is also amazingly flexible, supporting a large variety of SQL dialects and constructs, both as input and as output languages.
On SQL dialects
SQL is an odd language. First of all, it is a very old language, it is one of the oldest programming languages that is still being used. A lot has been written about the benefits and shortcomings of SQL. Despite SQL being standardized, my experience is that SQL programs are essentially never portable between different database systems. There is no such thing as a "standard SQL program". The official standard specification leaves many behaviors unspecified, and most, if not all, actual implementations diverge from the standard in some way. This huge variety of SQL dialects explains some of the complexity of Calcite: Calcite tries to be neutral and general as much as possible, to allow supporting any of these dialects. However, despite Calcite being a very flexible framework, it is not infinitely flexible. So you will find SQL constructs from various dialects that cannot be built using the standard Calcite parts. As an example, the Postgres DECIMAL data type supports "Infinity" values, which no other dialect does.
Caveat emptor
I am a newcomer to Calcite; I am learning about some of these parts by actively using them. One thing I have found is that the Calcite's project documentation is relatively sparse. So I have decided to write some blog posts about things that I have discovered, in the hope that this will make it easier for other people to use some of the tools in the Calcite toolkit. The caveat is that, because I am a newcomer, and because Calcite is very complex, I may get some things wrong. But hopefully, not completely wrong.
SQL parsers
Calcite is a framework for building SQL compilers. It is not a compiler, but it provides many pieces which can be assembled to build a compiler. For example, the Calcite codebase contains no fewer than 3 different SQL parsers, each of which is distributed as a separate JAR:
- the core parser, which supports the SQL query language (
SELECT * FROM ...), and the SQL Data Modification Language (DML): (INSERT INTO TABLE VALUES...,DELETE,UPDATE, andEXPLAIN) - the Babel parser, which extends the core parser, and supports many constructs that exist in various SQL dialects, such as the
::syntax for infix casts from Postgres, or several date-specific functions such asDATEADD - the server parser, which extends the core parser and supports SQL data definition language (DDL) statements, such as
CREATE TABLEandDROP VIEW.
The Calcite parsers are written using the Java Compiler Compiler (JavaCC) parser generator language. The parsers are customized using the Freemarker template language.
In Feldera we wanted a parser that is a blend of all 3, and Calcite made it relatively easy to build it. I plan to describe the process of building a custom parser in a future blog post.
In the rest of this text we will focus on SQL queries, and ignore the DDL and DML sub-languages. So when we say "SQL program" we mean one or more "SQL queries."
Calcite program representations
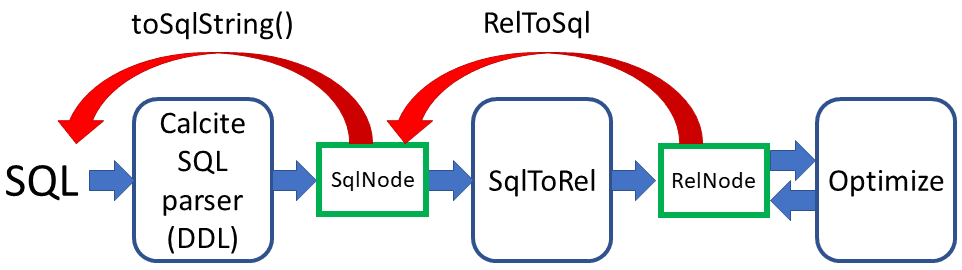
Like many other compilers, Calcite has several representations for programs. The following diagram illustrates how various tools transition between these representations:

Calcite Abstract Syntax Trees
A parser is a program that reads a string (in our case, a sequence of characters that is supposed to be a SQL program) and produces a data-structure that represents the structure of the parsed program. This structure is an abstract syntax tree, or AST.
In Calcite the AST is represented as a tree of objects that all derive from the SqlNode class.
Example
Consider the following SQL program:
CREATE TABLE T (
COL1 INT NOT NULL
, COL2 DOUBLE NOT NULL
, COL3 BOOLEAN NOT NULL
, COL4 VARCHAR NOT NULL
, COL5 INT
, COL6 DOUBLE
);
SELECT T.COL5 > T.COL1 FROM TThe following tree shows the essential parts of the representation of the query in this prorgam SQL program: SELECT T.COL5 > T.COL1 FROM T. Black arrows show Java field values, red arrows show the subfields of a Java object.

The relational program representation
The AST representation of a program is however not suitable for performing most program analyses and optimizations. So Calcite uses a second representation, the "relational" representation, which reflects the logical structure of the program compiled. (An AST reflects the syntactical structure rather than the logical structure.)
Moreover, while the parser rejects many malformed input programs, it will accept some programs that look superficially legal. So the conversion from the AST representation to the relational representation also performs deeper validation of the program. In particular, the conversion infers types for all program constructs and makes sure that these types satisfy the rules of the SQL programming language.
In Calcite the relational representation is also a tree of objects that all derive from the RelNode class.
Example
The following tree shows the essential parts of the relational representation of previous SQL.

Compare the two representations. You will notice that the RelNode has much more information. For example, nodes have been all annotated with type information. Notice that the table, the fields, the expression, and the operands all have type information attached.
In the Rel representation the dataflow is expressed in simpler terms. Instead of having complex SQL statements with WHERE, FROM, GROUP BY, etc. clauses we have a LogicalTableScan which reads table T and whose output is processed by a LogicalProject.
The expression representation (row expressions)
SQL is a two-level language: at the outer level it is a language that computes on relations (collections, or tables). The result of an operation like SELECT, FROM, ORDER BY, WHERE is always a relation. The collections contain rows, each composed of "scalar" values.
The inner SQL language is a language of operations on values that the collections are composed from. When one says SELECT a + b, or WHERE a > 2, a and b are such "scalar" values, and + is operation performed on scalar values. Calcite has a third separate representation for such expressions, which are called "Row expressions". The row expressions are also trees of objects that all derive from the RexNode class.
The SqlToRelConverter class is the one responsible for converting a tree of SqlNode objects into a tree of RelNode objects. The RexNode objects are subtrees of the RelNode tree.
The blue part from the previous diagram shows a RexNode, which is a subtree of the RelNode representation.
Optimizations
Calcite has a large repertoire of program optimizations; we will talk about some of these some other time. But all optimizations consume and produce RelNode trees.
Generating SQL code
Calcite has been used to compile queries for federated database systems, where a single query can operate on tables that reside in different databases, e.g., Oracle and SQL Server. For this purpose Calcite is used as a source-to-source translator, where the input query is translated into multiple queries, one for each database system that holds data, plus a piece of code that can be executed by a third party runtime, combining the results. (Calcite itself provides a runtime, implemented in Java, which can be used to execute SQL queries. It is used extensively for testing.)
In order to generate SQL, Calcite provides tools to go the opposite of the described route, from RelNode, to SqlNode, and finally to a SQL program. The RelToSqlConverter converts the relational representation back into a SqlNode tree.
Finally, SqlNode provides a method toSqlString to generate strings that represent SQL programs. One of the arguments of this method is a SqlDialect object, which ensures that the produced string is written using the dialect expected by a specific database. Eventually, the toSqlString method will call the SqlNode.unparse method of each node in the tree to produce the output program.
Visitors
The modern way to implement compilers, or, more generally, to write functional transformations over tree-shaped data structures, is to use the visitor pattern. Indeed, much of the Calcite codebase is implemented as various visitors that traverse the tree data structures and produce other tree data structures. Calcite provides base classes for the visitors, which can be extended by users. So we have three kinds of visitors, corresponding to the three IR kinds.
The SqlShuttle visitor is used to traverse SqlNode trees.
The RelNode visitor is used to traverse RelNode trees.
And finally, the RexVisitorImpl visitor is used to traverse expression trees composed of RexNode objects.
Comparing representations
The table below summarizes the three core Calcite program representations. We have talked about most of these rows. The "source position" row is about the representation maintaining information about the position in the original source program. Each SqlNode that was derived from the parser (but not the ones produced by the RelToSqlConverter) has a getParserPostiion method. This information is used by the validator, during the conversion from SqlNode to RelNode, to produce error messages pointing to the place in the source program where the errors are encountered.
Currenlty neither the RelNode nor the RexNode contain source position information. I believe that this is a mistake. Consider a SQL program that performs a division by 0. The code generated by Calcite cannot have enough information to point out which of the division operations in the source program has caused the runtime error. Hopefully this shortcoming will be fixed in the future.
| Criterion | SqlNode | RelNode | RexNode |
| Shape | Tree | Tree | Tree |
| Dialect-specific | No | No | No |
| Source Position | Yes | No | No |
| Visitors | SqlShuttle | RelVisitor | RexVisitorImpl |
| Validated | No | Yes | Yes |
| Typed | No | Yes | Yes |
| Can be optimized | No | Yes | Yes |




